в московской школе
Разработка программного обеспечения для генерации краткого содержимого выбранного текстового отрывка
|
Работа призёров конкурса проектов и исследований «Инженеры будущего» открытой городской научно-практической конференции «Инженеры будущего» в секции «Информационные технологии, программирование, прикладная математика, социальный инжиниринг» среди работ учащихся 10–11 классов |
Направление работы: Инженеры
Авторы работы: Университетский лицей №1511 предуниверситария НИЯУ МИФИ
Email: Написать
Предметы: Информатика
Классы: 10 класс
Мероприятия: Конкурс проектов и исследований «Инженеры будущего» открытой городской научно-практической конференции «Инженеры будущего» 2021 года
|
Актуальность
Ежедневно каждый из нас сталкивается с огромным информационным потоком. Нам часто необходимо изучить множество объёмных текстов (статей, документов) в ограниченное время. Сегодня мы переживаем эпоху информационного взрыва: за сутки человечество производит около 2.5⋅1018 байт информации.
Поэтому в области машинного обучения естественным образом родилась задача автоматического составления аннотации текста. Есть два метода: экстрактивный и абстрактивный. Для того чтобы лучше ориентироваться в информационном шуме и упростить задачу поиска нужных материалов, необходимо разработать алгоритм автореферирования текстовых отрывков и документов.
Цель
Разработать программное обеспечение, позволяющее генерировать краткое содержание выбранного текстового отрывка с сохранением смысла исходного текста.
Задачи
Задача проекта: создать Telegram-бот для генерации краткого содержимого выбранного текстового отрывка с сохранением его смысла.
Оснащение и оборудование, использованное при создании работы
- Ноутбук с установленным ПО (Python)
Описание
Пользователь отправляет исходный текст боту в мессенджер Telegram в одном из трёх форматов: pdf, изображение с текстом или текстовое сообщение.
Текст подготавливается к дальнейшей обработке: все слова в тексте лемматизируются, т.е. приводятся к формату Universal PoS Tags, удаляются стоп-слова и вводные конструкции.
С помощью библиотеки natasha с открытым исходным кодом создаётся граф зависимости слов в предложении, с помощью которого можно реализовать их сегментацию на более короткие для увеличения качества резюме: зачастую длинные предложения бывают похожи на большое количество других, что может привести к нагромождению текстовой выдержки.
С помощью заранее обученной и инициализированной модели word2vec для каждого слова из текста находится его векторное представление (все слова в модели представлены в виде векторов и имеют уникальный набор координат). Далее определяется вектор каждого предложения: отношение суммы слов-векторов к длине исходного предложения.
Так модель обучается на большом текстовом корпусе и строится на контекстной близости, тексты с одинаковыми словами будут иметь близкие (по косинусному расстоянию) векторы, отсюда можно легко определить схожие по смыслу предложения. Для этого создаётся пустая матрица подобия для хранения значений косинусного расстояния предложений, вычисляемых по формуле скалярного произведения векторов в n-мерном базисе.
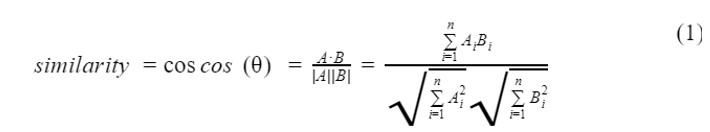
Преобразуем матрицу подобия в граф. Узлы этого графа будут представлять предложения, а рёбра – оценки сходства между предложениями. Здесь применяем алгоритм PageRank, чтобы получить рейтинг предложений:
- Если размер исходного текста достаточно большой, то и объём выдержки, способной сохранить его смысл, также будет немал. Поэтому для его уменьшения и составления резюме, близкого к аннотации, созданной человеком, был реализован метод абстрактивной суммаризации текста, основанного на архитектуре «кодировщика» и «декодировщика», сделанной с помощью Long short-term memory – типа нейронных сетей, способных к обучению долговременным зависимостям, обученной на новостных текстах и их заголовках.
- Окончательный результат отправляется пользователю в одном из трёх удобных ему форматах: pdf, mp3 файл (где начитывается краткое содержание) или текстовое сообщение.
Авторами рассмотрен комбинированный подход известных методик и техник, а также предложены методы его улучшения и модернизация, разработан telegram-bot для общения с пользователем, реализован представленный алгоритм суммаризации на языке Python 3.6.
Результаты работы/выводы
|
Наш алгоритм |
Чужой алгоритм |
|
|
ROUGE – 1, p |
0.15 |
0.1 |
|
ROUGE – 2, p |
0.07 |
0.05 |
|
ROUGE – L, p |
0.16 |
0.11 |
|
ROUGE – 1, r |
0.30 |
0.2 |
|
ROUGE – 2, r |
0.12 |
0.11 |
|
ROUGE – L, r |
0.27 |
0.24 |
Процент сжатия исходного текста находится в диапазоне 25–30 процентов. Порядок слов, а также основная мысль исходного текста сохраняются. Абстрактивный метод на данный момент показывает не очень хорошие результаты. Это связано с тем, что модель была обучена на небольшом наборе данных. Обработка больших Data Set требует значительно большего времени и вычислительных ресурсов.
По данным метрик ROUGE-N, ROUGE-L, в сравнении краткого содержания, которое выдал алгоритм, с редакторским пересказом, авторский превосходит показатели аналогичных программ, которые на данный момент доступны в русскоязычном сегменте интернета. Для решения проблемы абстрактной суммаризации (создание пересказа, похожего на редакторский) был выбран метод аугментации текста – метод построения дополнительных данных из исходных при решении задач машинного обучения, показывающего неплохие результаты.
Перспективы использования результатов работы
Результаты работы могут быть использованы в различных прикладных задачах: суммаризация множества веб-страниц и др.
Сотрудничество с вузом при создании работы:
НИЯУ МИФИ
Мнение автора
«Наш проект позволил глубже погрузиться в тему NLP и машинного обучения. Открытая научно-практическая конференция «Инженеры будущего» – замечательное мероприятие для учащихся школ России, которое позволяет раскрыть свои таланты»
- Сборник тезисов проектных и исследовательских работ победителей и призёров открытой городской научно-практической конференции «Инженеры будущего» 2025 года
- Сборник проектных и исследовательских работ победителей и призёров открытой городской научно-практической конференции «Инженеры будущего» 2024 года
- Сборник проектных и исследовательских работ победителей и призёров открытой городской научно-практической конференции «Инженеры будущего» 2023 года
- Сборник проектных и исследовательских работ победителей и призёров открытой городской научно-практической конференции «Инженеры будущего» 2021 года
- Каталог проектных и исследовательских работ участников, победителей и призеров открытых городских научно-практических конференций 2019 года
- Энергия моря: «Морской змей»
- Анализ влияния покрытия на эффективность солнечных элементов
- Сайт мониторинга энергобаланса энергоактивного здания (GREEN SITE)
- Электролиз. Генератор водорода
- Модификация ветрогенератора
- Исследование возможности использования ветрогенераторов в мегаполисе
- Эпоксидная смола и её взаимодействие с разными факторами
- Зелёный водород – основа энергетики будущего
- Приливная электростанция (ПЭС)
- Получение «зелёного» водорода на ГЭС с использованием новых наноматериалов
- «Зелёный» бойлер – нагреватель на основе возобновляемых источников энергии (GREEN BOILER)
- Создание водородного реактора своими руками
- Умная подсветка лестничных пролётов
- Оценка механических свойств перспективного паяного соединения вольфрам/сталь применительно к термоядерному реактору DEMO
- Применение электронного прогибомера для фиксации перемещений пролётного строения при мониторинге продольной надвижки
- Система обеспечения современного дома сжатым воздухом
- «Зелёная школа» – энергоактивное здание будущего (GREEN SCHOOL)
- Создание мобильной высокомощной солнечной панели для походных условий
- Моделирование архитектурных украшений Исаакиевского собора
- Модульная муравьиная цивилизация
- Влияние сточных вод аэродрома на рост микрозелени
- Экономическая игра
- Дизайнерские часы с ночной подсветкой, будильником, возможностью выбора часового формата
- Создание дизайн-проекта «Лаунж-зона» в школе старшеклассников
- Разработка экспресс-теста на глютен методом иммунохроматографического анализа
- Исследование влияния замещения ионов Ca2+ на Sr2+ на биологическую совместимость октакальций фосфата in vitro
- Получение и изучение новых антипиренов, модифицированных нано-TiO2∙nH2O
- Новые железосодержащие наноматериалы для очистки воды
- Аптечка первой помощи, укомплектованная антисептическими полимерными материалами
- Получение изоиндолкарбоновых кислот для их тестирования на противомикробную активность
- Дезодорация и дезинфекция воздуха в школьных помещениях при помощи органических фильтров
- Синтез холестериновых производных анти-ВИЧ-нуклеозидов в качестве перспективных ингибиторов обратной транскриптазы ВИЧ
- Исследование коллоидных растворов нитрида титана и серебра, полученных методом фемтосекундной лазерной абляции в жидкости, как наносенсибилизаторов для борьбы с онкологическими заболеваниями
- Метатезисный селенсодержащий рутениевый катализатор полимеризации
- Разработка альтернативных методик удаления пятен с поверхности ткани и анализ их эффективности
- Оценка микропластика как угрозы планетарного масштаба на примере исследований бутилированной воды
- Выделение лишайниковых кислот и создание косметического средства на их основе
- Использование в арт-индустрии метода гальванопластики органических тканей на примере омеднения скелетированных листьев растений
- Восстановленный оксид графена как анодный материал для металл-ионных аккумуляторов
- Синтез гидрофобного вектора на основе дипальмитоил-амино-пропан-2-ола для создания пролекарственных производных нуклеозидных препаратов с выраженной анти-ВИЧ-активностью
- Эффективность применения полимерной биоразлагаемой подложки для увеличения скорости прорастания сельскохозяйственных культур
- Определение растворённого кислорода в суккулентах различных видов методом Винклера
- Влияние концентрации источников углерода и азота в среде на рост бактерии Methylorubrum extorquens
- Получение защитных покрытий на низкоуглеродистой стали в нейтральном нитратном оксидирующем растворе с добавками мочевины
- Баллистическая оболочка туловища из углеарамида
- Термоиндуцированное сжатие полиэлектролитных капсул с магнитными наночастицами в оболочке
- Поиск возможности биоразложения композитов на основе полиэтилена и крахмала
- Свободные радикалы в волосах человека и их изменение при химической и термической обработке
- Предложения по принципиальной конструкции универсальной энергонезависимой установки для очистки воды из родников
- Выделение и исследование наночастиц городской пыли Москвы
- Регенеративный патрон на основе пероксо-модифицированного нано-TiO2
- Экоскейт. Использование вторсырья в изготовлении скейт-досок в домашних условиях
- Разработка интерактивной зоны на территории школы с элементами ландшафтного дизайна
- Звуковая волна
- Усовершенствованный вариант тисков Моксона
- Модернизация системы вентиляции и кондиционирования воздуха здания школы
- Утилизация и вторичное использование отходов резинотехнических изделий (на примере стирательных резинок)
- Обустройство воинского мемориала в деревне Веригино
- Использование витражной росписи как одного из элементов декорирования интерьера (на примере столовой ГБОУ Школа № 2005)
- Экокрыша школы будущего
- Создание лекарственного средства, не проявляющего гепатотоксичность, на основе парацетамола и глутатиона
- Разработка плёночных съедобных биоразлагаемых покрытий на основе хитозана
- Улучшение качеств хитозана посредством модификации
- Разработка термостабильного состава для ПЦР-наборов
- Система управления водоснабжением дачного участка
- Ветроархитектура
- Скейт-парк
- Разработка и создание дизайна IT-полигона школы № 1573
- Школьная среда как элемент социального конструктора
- Синтез и свойства 1,5-диметил-3,7-дизабицикло[3.3.1] нонан-9-она
- Сравнение методов пробоподготовки при определении подвижных форм металлов в почвах
- Создание школьного спектрофотометра на основе Arduino
- Роторная парковка карусельного типа
- Возможности химиотерапии: синтез цитоксических соединений платины
- Методика нанесения защитной маркировки документов с помощью флуоресцентных красителей
- Место ли пластику в косметике?
- Создание фильтрационных половолоконных мембран для фракционирования плазмозаменителей крови
- Радиационная безопасность в школе: измерение ионизирующих излучений и комплексный анализ
- Разработка брендбука ГБОУ Школа № 64
- Влияние электромагнитного излучения мобильных телефонов на людей
- Разработка автономной системы охлаждения лабораторного холодильника
- Ультразвук служит человеку
- И светит, и греет, или Как определить удельную теплоту сгорания топлива
- Изучение состояния воды в сухих ингредиентах спортивного питания методом ЯРМ
- Устройство оповещения о звуковых сигналах с помощью вибраций для неслышащих людей
- Анализ статистики потребления вредных продуктов, влияющих на возникновение рисков сахарного диабета среди подростков и начало прогнозирования на основании использования больших данных
- Рефлексометр. Измерение простой и дифференцировочной сенсомоторной реакции человека
- Изучение явления биений и его применение
- Дистанционное зондирование Земли
- Хранение мяса в условиях акустической заморозки и оценка его биотоксичности
- Макет футбольного поля с системой освещения на основе пьезоэлементов
- Разработка действующей модели автоматической поворотной двери с кинематикой Клеменса Торглера для IT-полигона
- Беседка для внутреннего дворика школы № 1195
- Игра «ANIMAL KEEPERS»
- Проект зонирования музейно-выставочного пространства «Корабль сказок»
- Модель дома из акрила с использованием 3D-печати
- Сегментация повреждений лёгких на КТ-снимках
- Протезирование кистей рук
- Автоматизированное взятие биоматериала с использованием системы технического зрения
- Навигационный прибор для слабовидящих и незрячих людей
- Разработка тренажёра для подготовки мышц к использованию бионического протеза
- Фотолитографический синтезатор олигонуклеотидов
- Медицинская маска и ген ACE2 – внешняя и внутренняя защита от COVID19
- Накладка на клавиатуру для людей с ограниченными зрительными возможностями
- Создание 3D-модели сцены по фотографии
- Клавиатура истинного разработчика
- Изменение магнитных свойств нанопроводов в зависимости от условий их получения
- Определение коэффициента трения качения методом наклонного маятника
- Пьезоэлектрическое напольное покрытие
- Маятники в искусстве
- Разработка технологического процесса изготовления камер сгорания для ЖРД малой тяги (14 кгс) с применением композиционных материалов
- Компьютерная лабораторная работа по изучению климата Земли на примере зонального распределения температуры
- Действующий макет гидравлического манипулятора
- Изучение теплопроводности различных материалов
- Формирование отчёта по лабораторным работам
- Осциллоскоп
- Изучение информации о ГЭС. Создание макета ГЭС
- Визуализация баллистического движения в Excel
- Технология сохранения свойств и особенностей белого камня (известняка) при реставрации и консервации памятников архитектуры
- Кинетическая обучающая проун-модель «Физика»
- Инновационный метод борьбы с синантропной флорой транспортных путей на примере борщевика Сосновского с помощью растений-ремедиаторов
- Двухэтапный метод измерения, визуализации и идентификации источников переменных электромагнитных полей путём картирования и спектрального анализа
- Создание устройства для наблюдения «живой» доменной структуры в ферромагнитных плёнках
- Приобретение навыков получения высокого переменного напряжения. Передача энергии без проводников
- Синтез и исследование коллоидных наночастиц нитрида титана для применения в биомедицине
- Система управления антенной при измерении параметров электромагнитных полей в целях технической защиты телекоммуникационной информации
- Перестраиваемый экран по принципу Бабине на основе метаматериалов
- Изучение газодинамической неустойчивости Кельвина – Гельмгольца с помощью гофрированной трубы
- Система автоматической газовой сигнализации
- Импульсный ускоритель масс и его применение для устранения космического мусора
- Автополив «AgroID»
- Разработка гидроакустической навигационной системы как способа беспроводной подводной связи
- Создание твитеров для воспроизведения высокочастотных звуков в составе домашней акустической системы
- Куртка с указателями направления движения
- Энергосбережение при освещении теплиц
- Пускозарядное устройство с расширенным функционалом
- Умная ваза
- Перспективная микропроцессорная модель управления СЦБ на железной дороге
- Проект настольного акрилового светильника с функцией подставки под мобильные устройства
- Создание полупроводниковой электроники плазменными методами
- Плата для источников бесперебойного питания
- Автоматизированная система контроля и поддержания нормы температуры и влажности в кабинетах школ
- Рабочая модель катушки Теслы
- Создание пожарного робота для работ в трудных условиях
- Отвод конденсата от кондиционера с помощью технологии ультразвукового испарения
- Программируемая RGB-кольцевая лампа на основе адресной светодиодной ленты
- Разработка стенда для тестирования ВМГ
- Применение комбинированного соединения обмоток в асинхронном электродвигателе
- Крепкая бумага
- Исследование наночастиц серебра и их применение в медицинских имплантах
- Исследование эффективности автономного хладогенератора для жидкостей
- Определение наиболее выгодного метода отопления жилого дома
- Увеличение мобильности инвалидов в городской местности
- Протез ноги из углепластика
- Проектирование устройства для криоконсервации крови на основе элемента Пельтье
- Создание модели БПЛА для обучения детей младшего школьного возраста основам пилотирования и развития у них интереса к авиации
- Создание установки для исследования теплопотерь различных материалов
- Технология создания макета «Дорога жизни»
- Создание модели школы и пришкольной территории в 3D-формате
- Умная зимняя теплица
- Создание практикума по теме «Постоянный электрический ток» с использованием модернизированных реохордов
- Исследовательская работа «Принцип композитности»
- Сравнительный анализ методов радиоволнового лифтинга, применяемого в современной косметологии
- Модернизация автоматического освежителя воздуха
- Сборка лампового гитарного усилителя и исследование принципа работы лампового усилителя звука
- Разработка и создание лампово-полупроводниковой радиолы
- Подводный робот для забора проб воды и грунта
- Разработка миниатюрного ультразвукового дальномера с цифровым дисплеем на базе Arduino для проведения измерений расстояний от точки до точки
- Умная теплица
- Создание автоматизированной системы полива комнатных растений
- Автоматизированная система для теплицы
- Создание системы для автоматической подачи корма и воды домашним декоративным птицам
- Водородный электролизёр с повышенным КПД
- Интерактивная таблетница на базе Arduino
- Интерактивный макет умного дома с реализацией управления через веб-интерфейс
- Браслет-поводырь
- Разработка модели бытовой сигнализации
- Создание аппаратной платформы для развивающих игр с RFID-полем
- Умный смеситель
- Изготовление форм методом вакуумного формования
- Разработка стабилизатора напряжения для питания полезной нагрузки малого космического аппарата
- Разработка системы управления гидропонной установкой
- Указатель курса ветра для обучения управления парусными судами
- Автоматическая система учёта времени на научных судах
- Система повышения безопасности велосипедиста на дороге
- Пляжный радар
- Домашний прибор для измерения давления, температуры и влажности
- Создание прибора для автополива растений на основе Arduino с управлением через приложение
- Терменвокс с использованием лазерных дальномеров
- Умный светильник
- Лазерная арфа
- Создание образовательного набора-конструктора для изучения темы «Алгебра логики»
- Аналитические весы для работы на научно-исследовательских судах
- Автоматическая штора с функцией накопления энергии
- Дозиметр и его принцип работы
- Система умного автополива комнатных растений
- Переносное зарядное устройство с возможностью подзарядки от солнца
- Образовательный конструктор Z80
- Создание усилителя звука для бюджетной системы звукового оповещения на небольших территориях
- Создание дешёвого и мощного регулируемого источника постоянного тока для инженеров и радиолюбителей
- Устройство измерения наполняемости мусорного контейнера
- Автоматический дозатор воды
- Система поддержания микроклимата в садовой теплице
- Устройство для помощи детям с плохо развитой моторикой и ухудшенной координацией
- Система контроля уровня воды в кулере
- Автономная система по уходу за растениями
- Гардеробот: Telegram-бот для выбора одежды по погоде
- ИнфоПост
- Конструктор диагностических систем
- Оценка потенциала территории европейской части РФ для использования солнечных батарей с помощью геоинформационных технологий
- Moscow metro as an alternative energy source / Внедрение альтернативных источников энергии на примере Московского метрополитена
- Разработка приложения для учёбы в виде визуальной новеллы
- Создание интерактивного приложения для подготовки к устному экзамену по китайскому языку (HSKK)
- Интерактивная карта народного искусства России
- Решение задачи коммивояжёра в трёхмерном пространстве
- Расшифровка языка жестов
- Использование распределённой сети при решении задач оптимизации с помощью эволюционных алгоритмов
- Приложение для учеников
- Конструкция вертикального озеленения рекреационных и учебных помещений ГБОУ Школа № 1564 «Вертикальный сад» с автоматизированным поливом для поддержания экологии школьной среды
- Автоматическая таблетница
- Контроль фильтров очистки воды
- Мобильное приложение Palladium (Цифровой завхоз)
- Создание мобильного приложения для изучения алгебры
- Mit App Inventor
- Система сигнализации на базе технологий умного дома
- Система контроля 3D-принтера посредством Телеграм-бота
- Программа «Антиплагиат» с графическим интерфейсом для файлов .txt и текстов
- Спектральный звуковой анализ в целях идентификации и классификации людей по голосу
- Генератор коллажа финишных материалов
- Автоматический распознаватель аккордов для гитары
- Навык Яндекс.Алиса Гардероб
- Безопасность цифровых активов
- Модуль анализа состояния посевов с помощью NDVI
- Кибербезопасность. Сетевые атаки
- Приложение для обработки фотографий, реализованное на языке программирования Python
- Анализ отзывов клиентов на банковские каналы обслуживания и продукты/услуги
- Искусственный интеллект для нашей теплицы
- Создание универсального интерфейса для работы с базами данных
- Чат-бот «Notify.Manga»
- LaTeX-редактор
- Голосовое управление для электронных шахмат
- Туристическое iOS-приложение с дополненной реальностью
- Нейронная сеть по распознаванию животных
- Интернет-ресурс «We-ask» – форум начинающих программистов
- Счёт на пальцах
- Умный дом. Умный свет
- Мобильное приложение для удалённого управления компьютером
- Разработка алгоритма распознавания жестов, применимого для систем компьютерного зрения и smart-перчатки
- Умное зеркало – будущее вашего дома
- Web-приложение для создания и обмена визитками
- Моделирование полёта космического аппарата
- Web-страница с информацией о потребительских качествах и физических свойствах компьютерных комплектующих
- Умный дом. Электросети загородного дома
- «Robot store»
- Анимация как инструмент восприятия информации подростками
- Приложение для расширения словарного запаса
- Рабочая тетрадь для виртуальных лабораторных работ
- Прибор для измерения скорости ветра (Анемометр)
- Создание прототипа интуитивной системы контроля над распространением коронавирусной инфекции в школьной среде
- Сервис для обучения основам алгоритмики. Машина Тьюринга
- Чат-бот для помощи в подготовке к итоговому сочинению
- Приложение для быстрой оплаты через «Систему быстрых платежей»
- АСВК-олимпиада (автоматизированная система выдачи ключей Всероссийской олимпиады школьников)
- Создание универсального приложения для записей, заметок и конспектов
- Автоматизация создания школьного расписания
- Разработка многофакторной аутентификации с применением электромеханического замка на основе GSM-модуля
- Приложение для отдыха и психологической поддержки
- Мобильное приложение для изучения китайских слов
- Telegram-бот для выявления дизорфографии
- Сервис для интеллектуального аннотирования (суммаризации) текста
- Создание нейронной сети для реставрации древнерусской иконописи
- Бот «Электрон»
- Web-приложение для заказа пропусков на территорию охраняемых объектов
- Искусственный интеллект для прогноза результатов спортивных матчей
- Разработка сайта для дизайнера
- Чат-бот «Школьник»: расписание класса, научные факты, теория по ключевым предметам – в твоём кармане!
- Разработка Telegram-бота для администрирования теннисной школы
- Реализация чат-бота в Telegram для решения задач по системам счисления: от простых до олимпиадных
- Устройство для распознавания лиц на энергоэффективных ядрах
- Создание информационного ресурса для обучения игры в баскетбол
- Webudget. Приложение для контроля повседневных расходов
- Распознавание автомобильных номеров
- Система помощи по соблюдению масочного режима на основе анализа видеопотока
- Компьютерное моделирование долгих прогулок с домашними животными: автоматический расчёт времени и пройденного пути, определение усталости в конце прогулки
- Дискорд-бот для обучения
- Simple Messenger
- Программа-ассистент для организации проектной деятельности
- Система мониторинга газоводоснабжения в помещении
- Разработка менеджера паролей «Tessera»
- Создание альтернативного метода шифрования
- Образовательный чат-бот по решению задач на круги Эйлера, реализованный на языке программирования Python
- Мобильное приложение «Пожарка»
- Интеллектуальная система распознавания лиц
- Разработка Телеграм-бота по профессиональной ориентации детей в сфере космонавтики на основе метода Дж. Голланда
- Система умных парт «SmartTab»
- Система аутентификации в образовательных учреждениях
- Разработка Web-приложения для изучения корейского языка в интерактивной форме
- Приложение для отслеживания присутствия на дистанционном уроке
- Пособие «Круговорот воды в природе» для слабовидящих детей
- Создание учебного пособия «Интерактивный музей следов зверей и птиц»
- Автоматизированный комплекс для химического анализа донных осадков
- Управление микроконтроллером ESP 32 CAM дистанционно с помощью интернет-ресурсов
- Разработка телеуправляемого необитаемого подводного аппарата как средства мониторинга состояния водных ресурсов
- Разработка автоматической линии по производству кондитерских изделий
- 3D-модель ДВС
- Разработка наглядного пособия по физике на основе конструкции Тенсегрити
- Миниатюрный станок с ЧПУ для фрезеровки печатных плат
- Создание инженерных лабораторий для поддержания работоспособности школьного оборудования
- Робот-кондиционер
- Модель плёночного фотоаппарата
- Мой манипулятор
- Управляемый штатив для съёмки фото и видео на телефон
- Настольная игра, адаптированная для незрячих и слабовидящих детей
- Модели двигателя внутреннего сгорания
- Штанга, выполненная из сверхпрочного композиционного материала, для крепления гибкой солнечной батареи космического спутника
- Автоматизация процесса диорамной съёмки в покадровой анимации
- Панобот
- 3D-сканер с использованием микроконтроллера Arduino
- WebLabory
- Создание 3D-пособий для слабовидящих детей
- Современный да Винчи
- Робот – уборщик игрушек
- Сервис для моделирования поведения и программирования квадрокоптеров в облачной среде «COEX-Cloud»
- Создание системы для улучшения досуга людей с ограниченными возможностями
- RoboAnt – многоцелевые роботы на базе универсальной шагающей платформы
- Универсальная платформа шагающего робота «КОТ»
- Создание головоломок в Autodesk Inventor Pro 2021
- Настольная игра «Пожелание»
- Шлем для альпинизма, выполненный из сверхпрочного композиционного материала
- Создание облегчённой ракетки для настольного тенниса, выполненной из сверхлёгких композиционных материалов
- Изготовление мастер-модели гребного винта
- Дорожные приключения
- Приложение для обмена опытом по профессиям
- Создание бота-консультанта в Telegram
- Информационное агрегирование волонтёрской деятельности по жизнеобеспечению бездомных животных
- Мобильное приложение – помощник в утилизации мусора
- Синхронизация полёта группы БПЛА
- Сопоставление эффективности методов оптимизации и уравнений при описании зависимостей избыточной мольной энергии Гиббса в бинарном растворе
- System of periodic body temperature monitoring under pandemic conditions based on a medical mask holder for educational organization employees/Система периодического мониторинга температуры тела сотрудников образовательной организации на основе держателя
- Creation of the interactive models for Moscow Electronic School with «1C: Mathematical Constructor» / Создание интерактивных моделей для московской электронной школы в программе «1С: Математический конструктор»
- Система ограничения скорости самоката
- Умная ёмкость
- Автоматизация гардероба
- Сайт с интерактивной таблицей Менделеева
- Генератор вариантов задач по алгебре для 8 класса с пятью уровнями сложности
- Создание учебно-методического модуля в предметной области химии
- Разработка и изготовление методом FDM-печати модели прототипа «Ополаскиватель для химической посуды» при помощи систем быстрого прототипирования
- Косметическая накладка анатомической формы для механизированного протеза ноги, выполненная с применением аддитивных технологий и реверс-инжиниринга
- Создание 3D-модели стартового пистолета с рабочим ударно-спусковым механизмом
- Сборно-разборная модель тазовой кости человека
- Использование аддитивных технологий при создании СВЧ-устройств
- Sкедуль
- Макет мобильного приложения «Моя культура»
- Hobynizer – удобный органайзер для вашего хобби
- Проектирование и изготовление композитного рюкзака
- Бионический протез человеческой руки на 3D-принтере
- На уроке физики был взрыв
- Речевое оповещение о приезде общественного транспорта
- Автоматизированная система мониторинга осанки человека
- Remember Bot – чат-бот школьного дневника
- Система обеспечения безопасности людей и транспорта на парковках в холодное время года
- Умное зеркало для отслеживания расписания
- «Смомби»: проблемы и решения
- Автоматический бесконтактный термометр АБТ-2100
- Создание обучающих видео для курса «Космическая вёрстка»
- Разработка web-приложения для повышения успеваемости учащихся через увеличение концентрации внимания
- Умная система прохода для учебных учреждений «NFC KEY»
- Устройство для экономии/контроля воды
- Система автоматического обнаружения неисправности электроосветительных приборов и подтопления подвальных помещений
- Система предотвращения происшествий во время движения спецтранспорта на перекрёстке
- Создание учебной модели ДНК для уроков биологии профильного уровня
- Сайт для помощи выбора прически «HairBrush»
- Создание приложения для поиска рецептов и организация взаимодействия авторов рецептов
- Система автоматизированного температурно-пропускного контроля (САТПК)
- Телеграм-бот для шифрования
- Термометрическая подставка
- Мобильное приложение экстренной помощи
- Вас распознали: автозаполнение посещаемости на основе распознавания лиц людей
- Разработка исследовательского микроспутника
- Создание леденцов на основе ягод клюквы болотной («Oxycoccus palustris») как источник иода для детского организма
- Разработка школьного транспортировщика питьевой воды
- Автоматизированный комплекс по сортировке мусора
- Телеметрическая система грузового железнодорожного вагона
- Роботизированный краулер
- Разработка контрольно-сортировочного автомата
- О возможностях и преимуществах применения компьютерного моделирования при испытаниях грузового подвижного состава
- Багги-карт
- Руль болида из композиционных материалов
- Создание электромагнитной установки для очистки околоземной орбиты от космического мусора
- Умный дом
- Исследование способов уменьшения сопротивления воздуха в закрытых пространствах за счёт вращательного движения
- Проект крепления противоугонного устройства велосипеда
- Разработка и создание полноприводного шасси радиоуправляемой модели автомобиля
- Ленточный станок гриндер
- Повышение городской и межгородской мобильности при помощи гравитационного транспорта
- Создание автономного необитаемого аппарата для подводной диагностики
- Проектирование радиационной защиты для головного обтекателя космического корабля
- Держатель коляски в общественном месте
- Оптимизация левого поворота у беспилотных автомобилей
- Создание действующей модели автомата перекоса тарельчатого типа для изучения процесса управления вертолётом
- Изготовление изделия из композитных материалов методом вакуумной инфузии. Открытие промышленного цеха
- Разработка универсальной манёвренной платформы
- Применение действующего кинетического стола и кинетической ленты как транспортной системы
- Влияние авиационного топлива на искусственное покрытие аэродрома
- Программа сравнительной оценки методов очистки светлых нефтепродуктов от примесей серы и сероводорода
- Живое яблоко
- Снегоболотоход. Разработка вездехода с эффективными и устойчивыми к низким
- Макет ж/д-переезда
- Цифровая тяговая подстанция
- Wise-soft – подвеска настоящего будущего инженера
- Чат-бот в Telegram для решения задач на графы
- Программа для подготовки к ОГЭ по математике «Остров Математики»
- Создание мобильного приложения «Музыкальный диктант»
- Школьная система хранения гаджетов
- Моделирование историко-архитектурной среды города с использованием геоинформационных систем и пакетов трёхмерной графики
- 3D-модель «Музыкальная шкатулка-рояль»
- Автоматическая межпланетная станция
- Создание прототипа бронежилета
- Создание модели кривошипно-шатунного механизма
- Проектирование мультимедийного приложения «Evology» с элементами дополненной реальности
- Прототип робота-снегоуборщика
- Разработка специальной одежды для людей с ОВЗ
- Мобильный медицинский робот для красных зон
- Система контроля школьников на выездных мероприятиях
- Интерактивная 3D-модель школы
- Концепт автобусной остановки «Аура»
- Интерактивный макет вагона метро
- Противоударная хоккейная маска
- 3D-модель роторного двигателя
- Создание прототипа домашнего ирригатора
- Создание набора улучшений к лазерным станкам с ЧПУ
- Разработка и визуализация оригинального дизайна рабочего места
- Модель турбореактивного двигателя
- Изготовление индивидуальных деталей для автомобиля
- Пособие-игра «3D-REBUS» с использованием AR-технологий
- Унификация игры «Зельеварение» с помощью 3D-моделирования
- Модель устройства для переплавки пластиковых отходов в нить для 3D-печати
- Фотопанорамные 3D-VR туры на примере проектов «Виртуальный музей Московского метрополитена», «Вечерняя Москва», «Павильон авиации и космонавтики № 34, ВДНХ»
- Использование аддитивных технологий в преподавании черчения
- Солнечная система в дополненной реальности
- Создание симулятора выживания в виртуальной реальности
- Изготовление модели ордена Святой Великомученицы Екатерины на 3D-принтере
- Доступная модель протеза ноги на 3D-принтере
- Создание экспоната для школьного музея «Мастер танковых ударов» пулемёт ДТ-29
- Запорно-регулирующая арматура
- Автономная уличная система кормления для животных
- Устройство для контроля осанки
- Создание экспериментальной модели робота-эколога для мониторинга лесов
- Опорно-поворотная платформа с модулем наведения антенны
- Робот, объезжающий препятствия с помощью ультразвукового датчика расстояния
- Беспилотный летательный аппарат и система управления им, основанная на Arduino
- Искусственный интеллект своими руками
- Использование современных материалов и технологий при конструировании спортивной авиамодели
- HelpUnicorn: платформа для IT-помощи благотворительным организациям
- Применение обратной теоремы Пифагора для определения вида треугольника
- Робот-Колобок
- Устройство контроля и поддержания оптимального микроклимата в учебном заведении
- Ракета
- Дрон-поисковик из сверхлёгких композиционных материалов с использованием углепластикового каркаса, бесколлекторных моторов и солнечной батареи
- Разработка робота-манипулятора с использованием омни-платформы и цепного подъёмника
- Умный медицинский робот-ассистент «ADI»
- Food Factory
- Разработка системы автоматизации внутрискладской логистики грузов
- Создание автоматической системы полива растений на загородном участке
- The backpack «Cyberbag» made of ultralight composite materials with an alarm lighting system / Рюкзак «Cyberbag», выполненный из сверхлёгких композиционных материалов, со светодиодной системой оповещения
- Система экстренного отключения подачи газа и воды
- Умный фонтан «Обитатели морских глубин»
- Умный термометр
- Визуальная новелла как подход к вовлечению изучения русской литературы, способствующий проявлять инициативность в осуществлении действий
- Устройство «Помощник для сбора рюкзака»
- Интерактивный макет умного дома с реализацией управления через веб-интерфейс
- Умная урна «UKU»
- Учебно-методический набор для изучения работы логических элементов и схем
- AR-приложение для школьных библиотек, демонстрирующее атмосферу книги – «Illustart»
- Artificial intelligence as an effective classroom assistant / Искусственный интеллект – эффективный помощник учителя
- Инновационные решения умного города
- Создание устройства для контроля состояния дорожного полотна
- Автоматизация распознавания занятости парковочных мест, отмеченных знаком 8.17
- Разработка электронных программируемых конструкторов POV-дисплея для образования и развлечения
- Модифицированный модуль для предоставления доступа к местам маломобильных и пожилых пассажиров в автобусе
- Поисковое устройство «Эврика»
- Инновационные способы изучения литературных произведений с использованием платформы izi.travel и Emaze Creative Editor, видеоредактора Movavi
- Ультразвуковой дальномер
- Организатор рабочего места
- Умный дом на Arduino (Smart House)
- «Нейродиагност» – приложение для помощи в определении диагноза (NEIRODIAGNOST)
- Прибор для контроля дыхания в домашних условиях
- Микробиологический анализ воды реки Клязьма
- Программное обеспечение для изучения работоспособности мозга
- Протез с силомоментным очувствлением
- Создание умной таблетницы «Smart Pill Box»
- Программная реализация модели сборки генома
- Изучение видового полиморфизма ДНК мяты перечной
- Идентификация хвоща полевого в сухом чайном напитке с помощью ДНК-маркёра
- Система безопасности Student Lock
- Звуки флейты сякухати донеслись из принтера
- Создание компоновочной схемы фандомата для утилизации алюминиевых банок
- Зонт «free hands»
- Анимированная 3D-модель советско-российской гусеничной десантной машины БМП-2
- Использование VR- и AR-оборудования для проведения экспериментов по физике в школах
- Устройство контроля по уходу за комнатными растениями
- Изготовление лангета для животных с использованием аддитивных технологий
- Создание 3D-моделей архитектурных элементов
- «Гибрид-1». Создание 3D-модели гибридного беспилотного летательного аппарата для многофункционального использования
- Устройство для съёмки 3D-панорамы
- Разработка школьной айдентики (Разработка фирменного логотипа. Графический дизайн)
- Приложение виртуальной реальности для релаксации и отдыха – «DistantRest»
- Применение радиоактивных отходов природного и техногенного происхождения в качестве альтернативных источников энергии
- Система адаптивного освещения
- Конструирование лодки на солнечных батареях
- Использование энергии солнца и дождевых капель в качестве альтернативного источника электроэнергии
- Приложение под виртуальную реальность для создания дизайна квартир
- «Умный» светильник
- Купол церкви из композитных материалов
- Проектирование сельских зданий и сооружений для территорий, подверженных наводнению
- Детская развивающая мебель
- Разработка дизайна подъезда многоквартирного дома
- Проектирование и разработка программного обеспечения синтеза трёхмерных моделей типовых зданий
- Концепция реконструкции площади Санта Кроче
- Микробиологическая оценка метрополитена
- Биореализуемый материал с антибактериальными свойствами для изготовления ожогового пластыря
- Качество молока
- Спектрофотометрическое исследование растворов сульфатов кобальта(II) и никеля(II)
- Разработка нанодисперсий на основе конъюгата α-липоевой кислоты и пропандиола с антиагрегационной активностью
- Влияние состава катализатора на показатели процесса дегидрирования изопропилового спирта
- Синтез производных индолил-3-масляной кислоты
- Изучение влияния условий хранения на пригодность питьевой воды
- Кто яблоко в день съедает, тот у врача не бывает
- Синтез полиглицерилфосфатов модифицированного строения как потенциальных ингибиторов адсорбции ВИЧ
- Материал и имплантат для восстановления хряща ушной раковины
- Центробежная сила. Её проявление в природе и применение в технике
- Расчётно-экспериментальное исследование баллистики страйкбольного оружия
- Заглублённые мусорные контейнеры
- Проектирование инновационной автобусной остановки для использования в городской среде
- Малые архитектурные формы – поддержка биоразнообразия на промышленных предприятиях
- Программируемая гирлянда на основе адресной светодиодной ленты
- Осуществление обучения учеников с ограниченными возможностями здоровья в общеобразовательной начальной школе
- Разработка энергоэффективной системы вентиляции и кондиционирования воздуха образовательной организации
- Проект цветника на воинском мемориале в деревне Веригино
- Опыт визуализации отдельных существующих и исчезнувших сооружений Москвы посредством программ для трёхмерного моделирования и геоинформационных систем
- Разработка настольной игры «Инженерный мир котиков»
- Практикум для решения задач ОГЭ (макет)
- Разработка новой технологии возведения сборно-разборных архитектурных сооружений
- «Умная» автобусная остановка
- Изучение процесса кавитации и возможности практического использования метода кавитации для обезвреживания и преобразования отходов заготовки и переработки древесины в полезную продукцию
- «Умная» теплица
- Автоматизация выбраковки упаковок тест-полосок для глюкометров
- «Ультралокальные» системы выращивания растений
- Автоматическая кормушка для рыб
- Разработка и создание исследовательского микроспутника
- Цветовой определитель «Color Detect»
- Изменение электрического сопротивления тензорезисторов при деформации
- Цифровой термометр
- Модифицированный датчик линии для робототехнических устройств
- Система отпугивания птиц (робот-пугало)
- Пьезоэлектрический эффект и его использование
- Многофункциональный светильник с дистанционным выбором режима работы
- Создание солнечного датчика
- Система контроля нагрузки на ось грузового автотранспорта
- Пневматическое метательное устройство для военно-тактической подготовки
- Преобразователь азбуки Морзе
- Программируемый бюджетный портативный IC-автомат для диагностики и проверки логики цифровых микросхем
- Аналитические весы для работы в условиях морской качки на научных судах
- Универсальное реле. Реле времени и термореле в одном устройстве
- Кодовый замок на релейной схеме управления и на программируемой плате Arduino
- Автоматическая система кормления для домашних животных
- Робот-рыбак
- Прототип выключателя для «умного» дома
- Разработка панели управления для комбинированного электро-твёрдотопливного котла отопления
- Кодовый замок
- Автоматизированная система выращивания растений «Smart greenhouse» с голосовым ассистентом
- Разработка кодового замка на базе микроконтроллера Arduino
- «Часы рабочего времени»
- «Умная» урна
- Создание звукового детектора электромагнитных волн
- Портативная интеллектуальная метеостанция с функцией управления «умным» домом
- Куб-компаньон для управления IoT-устройствами
- Переноска с электрообогревом
- Гитарный эффект
- Голографическая призма
- Гравитационный транспорт как новый вид городской и межгородской мобильности
- Устройство для автоматической сортировки мусора
- Роботизированный комплекс прокладки городских коммуникаций
- Проблема строительства и эксплуатации Северного широтного хода
- Аэросани
- Использование ракетоплана для формирования погодных условий
- Моделирование и прототипирование модели электромобиля «RE ROSSO E20»
- Система блокировки зажигания
- Интеллектуальная система навигации для «умного» города
- Модель гражданского самолета «ОГЛ-1»
- «Лежачий полицейский» на основе неньютоновской жидкости
- Создание прототипа универсального вездехода «ALLTER»
- Самолёт-квадрокоптер
- «Антисон 2» – устройство безопасности водителя автомобиля
- Использование дирижаблей для выполнения авиационных работ
- Генерация энергии
- Модифицированная доска для сёрфинга с подводным крылом на электрической тяге
- Мобильная буровая установка
- Создание спортивного трицикла
- «Умный» транспорт современного мегаполиса
- Двигатель Стирлинга
- Чат-бот «BotMusician»
- Автоматизированная система оповещения водителя о въезде в жилую зону
- Научная симфония: связь музыки и науки
- Модель скейтборда «эскимо» с электронным набором, выполненная из сверхлëгких композиционных материалов
- Модель первой русской подводной лодки
- Создание управляемого карт-тягача минимальной себестоимости из подручных материалов
- Внедрение холодного газодинамического напыления высокого давления в процесс ремонта турбореактивного двигателя
- Радиационная защита для космических кораблей
- Тренажёр для трейдинга
- Создание тестов для самостоятельного изучения и самоконтроля изучаемого материала
- Создание приложения-переводчика с языка программирования Pascal на язык программирования Python
- CLASSTEST – онлайн-платформа для тестирования знаний школьников
- Электронный каталог школьного музея «Добровольцы»
- Сайт зоомагазина
- Определение места жительства по социальным сетям
- «Бабушкина пряжа»
- Приложение Polymonial Calc
- Комплекс выявления неправомерной парковки транспортных средств
- Разработка умного справочника на базе Telegram-бота
- Разработка сайта для тестирования программ
- Дополненная реальность
- Платформа онлайн-тестирования
- Нахождение коэффициентов в химическом уравнении
- Скорочтение
- Здоровье школьника
- Интерактивная игра «Обезвреживание бомбы»
- Образовательный чат-бот на языке программирования Python «Тренажёр по решению комбинаторных задач и задач на множества»
- Создание бота в Discord для онлайн-мониторинга игрового профиля
- Web-технологии, dev-ops, организация сервисов, менеджмент трафика
- Социальная сеть Comject
- Картографирование железнодорожного транспорта в районе города Якутска
- Автоматическая система сортировки бытовых отходов для мусоропровода
- Арктика Interactive: создание интерактивной карты полезных ископаемых в Арктической зоне России
- Разработка программного обеспечения для генерации краткого содержимого выбранного текстового отрывка
- Виртуальная художественная 3D-галерея «Женщины в Великой Отечественной войне»
- Консольное приложение для изучения криптографических алгоритмов Crypto.App
- Сайт-форум с тематикой «Информационная безопасность»
- Создание программы «Тренажёр устного счёта: Умножение»
- Simply Food – это просто питаться правильно
- Математический тренажёр «Brain Storm»
- ALUB фоторедактор
- Создание интернет-ресурса SCHGK для поиска турниров по спортивному «Что? Где? Когда?» для школьников
- Исследование цифровых методов инженерного анализа на примере решения модельных задач
- Разработка онлайн-тренажёра для тренировки устного счёта
- Расчёт и визуализация траектории малого космического аппарата на высокоэллиптической орбите
- Android-приложение Student Assistant
- Создание Telegram-бота на языке Python для удалённого доступа к компьютеру
- Построение карты пространства на основе видео-стереопары
- Система интеллектуального мониторинга социального дистанцирования
- Разработка робота для игры в «Крестики-нолики»
- Автоматическая система ячеек для хранения личных вещей
- Робот-исследователь для видеоинспекции труднодоступных мест
- Постройка судна на беспилотном управлении
- Разработка системы навигации внутри роботизированной складской ячейки
- Оценка сокращения выбросов парниковых газов от реализации проекта в области концепции ответственного потребления
- Вирус-краудсорсинг
- Синхронизированный полёт группы БПЛА
- Продуктиндер
- Smart Mirror – зеркало «умного» дома
- «Умная» колонка с функцией «Озвучивание рецепта либо списка ингредиентов блюда по запросу»
- Электронный арбитр для интеллектуальных игр
- Усилитель работоспособности (Work Booster)
- Инженерное решение по повышению безопасности дорожного движения для велосипедистов
- «Умный» стилус
- Меню-конструктор «FOODIE»
- RGB-Плинтус
- Модульная программно-аппаратная платформа для освоения разработки микропроцессорных систем
- Школьный самокат
- Программно-аппаратный комплекс автоматизации открывания дверей
- Модернизация крытого спорткомплекса школ
- Макет онагра с системой управления голосовыми командами
- Создание теплицы с автоматическим поливом растений
- Динамика изменения показателей качества воды в роднике № 39 Тропарёвского лесопарка г. Москвы. Предложения по внедрению энергонезависимой системы очистки родника
- Эффект магнитной левитации на основе 3D-моделирования
- Робототехнический конструктор на базе платформы Ардуино
- Создание учебного 3D-макета человеческого зуба для уроков биологии
- Школьный музей с применением AR-технологии (Augmented Reality)
- Основные этапы проектирования, разработки и реализации шлифовального станка с использованием 3D-моделирования
- За страницами учебника геометрии: дополненная реальность
- Мобильный учебный класс для изучения астрофизики
- AR-технологии и их использование
- Интерактивная модель таблицы Д.И. Менделеева в AR
- «Умная» защита от протечек (УЗОП)
- Инвалидная коляска с функцией спуска и подъема по лестнице
- Автоматизированный помощник «ТОЧКА» для занятий рисованием
- Инновация накопителей: как сделать энергосистему более гибкой, дешёвой и экологичной?
- Контроль доступа по биометрическим параметрам
- Сравнительный анализ содержания «живых» лактобактерий в молочных продуктах на примере йогуртов различных производителей
- Исследование методов мультиклассификации клеток костного мозга
- Проектирование и изготовление композитного рюкзака
- Web-сервис для тренировки межпредметных знаний в игровой форме
- Викторина на знание среды программирования Scratch
- Разработка программы для прохождения аудита на соответствие двум стандартам информационной безопасности для российских и международных платежных систем
- Разработка распределённой системы дистанционного мониторинга уровня воды в кулерах
- Генерация отзыва о вузе при помощи Telegram-бота
- Создание квест-игры по заданиям ОГЭ по математике
- Разработка чат-бота для взаимодействия с расписанием школы
- Web-сервис для оперативного обмена исходным кодом
- Компьютерная система обработки текста, содержащего нецензурную лексику
- Сурдо-тренажёр (СТ)
- Мобильное приложение «Рецепт из подручных ингредиентов»
- Создание устройства для лиц с нарушениями зрения, помогающего ориентироваться на местности
- 3D-корсет (для травмированных конечностей)
- «Умный» город. Улучшение транспортной доступности в районе Нагатинский затон
- Дизайн-проект многофункционального школьного помещения
- Создание цифровой 3D-модели микрорайона
- Создание AR-модели «Солнечная система» с возможностью реализации приложения в МЭШ
- 3D-принтер Prusart
- Приложение виртуальной реальности для сборки электрических схем
- Информационный стенд об экологии в дополненной реальности
- 3D-модель беседки из вторсырья (поддонов, палет)
- «Умный» обогреватель
- Автоматизированный вагон метро
- Умный свет
- Создание виртуального музея физических приборов
- Интерактивный фонтан у северного выхода станции метро «ЦСКА»
- Дрон-доставщик
- Макет «вечного двигателя»
- Разработка украшения-носителя в Вlender
- Разработка интерактивных лабораторных работ
- Приложение дополненной реальности «Geometry AR»
- Создание удобного стационарного фена для людей с ограниченными возможностями
- Система поддержки передвижения маломобильных людей «Попутчик»
- Разработка модели персонажа для игры жанра rougelike
- Цифровой образовательный продукт «PAUTINA»
- Светофор с датчиком движения
- Чат-бот Telegram по подготовке к экзамену по английскому языку
- Автоматизированная система для проветривания помещений
- Роль пластика в загрязнении окружающей среды, мой вариант его вторичного использования
- Видеоэкология – наука для жизни
- Противоопухолевый комплекс олова на основе глицирризиновой кислоты
- Вода, которую мы пьём. Универсальный прибор для очистки воды
- Синтез альфа-линоленовой кислоты. Создание эмульсии на основе ненасыщенных жирных кислот
- Объединение нанотехнологий и наноматериалов с полимерами с целью получения полимеров с новыми свойствами
- Разработка методики сравнения антиоксидантной активности эфирных масел сосны и апельсина
- Химический состав бальзама для волос: влияние компонентов состава на структуру волоса
- Составление технологического справочника с целью дальнейшего использования на производстве
- Синтез и подтверждение структуры перспективного противогрибкового агента
- Компактный водородный реактор
- Подбор физико-химических условий для повышения КПД микробного топливного элемента – перспективного источника энергии на предприятиях
- Фильтрация микрочастиц
- Получение антибактериального композита на основе нанотрубок галлуазита
- Синтез 1,3-дипальмитоилглицерина и гидрофобного вектора на его основе
- Комбинирование анионных и неионогенных смачивателей для использования в лакокрасочных рецептурах
- Получение и изучение новых антипиренов, модифицированных нано-TiO2∙nH2O
- Новые железосодержащие материалы для очистки воды
- Почему возникают тайфуны, или Нагреваем воду сверху
- Учебное пособие-модель «Теллурий»
- Рефлектор зеркальных космических антенн межспутниковой связи из композиционных материалов
- Распространение лазерного излучения в оптически неоднородных жидких средах: на примере явления «ФАТА-МОРГАНА»
- Дискретный теплоаккумулятор, устройство для накопления тепла и передачи его внешнему объекту
- Исследование концентрации углекислого газа в помещениях
- Автоматизированная мобильная система кормления крупного рогатого скота
- Исследование магнитооптических свойств феррит-гранатов с различными примесями
- Определение механических характеристик разработанного многокомпонентного сплава на основе алюминия и возможности его использования в качестве материала автомобильного диска методом компьютерного моделирования
- Автоматизация предметного столика поляризационного микроскопа
- GeoGebra. Виртуальный стенд для интерактивных физических демонстраций по разделу «Геометрическая оптика»
- Ветровой генератор как альтернативный источник электроэнергии в загородном доме
- Многоканальная система автоматического полива растений
- 3D-левитрон. Установка для создания стоячих звуковых волн
- Определение нагрузочной характеристики контактного датчика силы
- Поиск оптимальных параметров выращивания скелетных кристаллов висмута
- Проект ракеты с твердотопливным двигателем
- Микрогидроэлектростанция своими руками
- Портативный прибор для измерения сердцебиения плода
- Автоматическая система управления отоплением загородного дома
- Гальванически изолированная система управления мощным источником питания
- Специальный коврик с беспроводной зарядкой
- Специальная система для считывания текста Брайля и последующего его перевода в латиницу и кириллицу
- Манипулятор в виде человеческой руки с отдачей ощущений
- Роботизированный комплекс для химического анализа донных осадков
- Устройство автоматической стабилизации и контроля беспилотного летательного аппарата SILF
- Bio-Hatchery Helper
- Роботизированный подводный аппарат
- Разработка прибора для измерения параметров воздушной среды
- 3D-анимация скелетной мускулатуры тела штангиста
- Помощник слабослышащего – электронное ухо (Electronic Ear)
- Разработка мобильного бинарного комплекса «TASF» видеофиксации состояния территориально распределенных объектов
- Разработка прототипа устройства для тестирования программ управления автономным полётом беспилотного летательного аппарата
- Автоматизированный террариум «Hometerra»
- Разработка прототипа кобуры для страйкбольного пистолета Glock
- Разработка и демонстрация функционирования системы мониторинга состояния человека в специальных стационарах
- Храм Иконы Владимирской Божией Матери
- Робот для прокладки коммуникаций «TechnoWorm D200»
- Бесконтактный санитайзер
- Создание 3D-пособий для слабовидящих детей «Alias» по-новому»
- Энергия моря: Морской змей
- Внедрение альтернативных источников энергии на примере метрополитена
- Разработка и создание управляемой модели двухосной системы ориентации солнечных панелей
- Система безопасного освещения лестничных пролётов
- Солнечный чехол для зарядки смартфона (Solar Case)
- Виртуальный мебельный магазин
- Витражная роспись как способ декорирования интерьера школьной столовой (на примере ГБОУ Школа № 2005)
- Проектирование 3D-модели современной школьной столовой
- Разработка модели мобильной осветительной системы
- Разработка школьной айдентики
- Сравнение концентрации каротиноидов в моркови и в филе рыбы семейства лососёвых
- Экспрессное профилирование жирных кислот в плазме крови человека методом масс-спектрометрии MALDI
- Создание универсального термоинтерфейса
- Получение бальзама для губ в домашних условиях
- Синтез и строение координационных полимеров переходных металлов с анионами замещённых малоновых кислот и мостиковыми N-донорными лигандами
- Изучение срока годности сока в пакете после вскрытия по микробиологическим показателям
- Новые матричные соединения для экспрессного детектирования действующих веществ в лекарственных формах методом масс-спектрометрии MALDI
- Получение экологичных строительных материалов с водоотталкивающими и противогрибковыми свойствами
- Безопасное производство с применением аммиака
- Многоразовые, высокоэффективные тест-полоски для глюкометра
- Создание противоопухолевого препарата на основе природного хлорина и соединений платины
- Синтез нано-Ag и получение на его основе полиакрилатных противоожоговых гидрогелей
- Создание одноступенчатой ракеты и исследование её аэродинамических свойств
- Способ автоматического регулирования плотности раствора и программное обеспечение автоматического управления технологическим процессом
- Физика в играх
- Исследование пределов реализации течения коанда и образования зоны турбулентности при обтекании цилиндрических тел с помощью объекта science art «незаметная бутылка»
- Лабораторная установка для измерения скорости звука
- Возможный способ реализации термодинамического эффекта извлечения влаги из воздуха методом конденсации в задаче индивидуального обеспечения водой личных подсобных хозяйств в условиях Крымского полуострова
- Разработка метода генерации электроэнергии из систем городского водоотведения
- Применение звукового датчика уровня жидкости для людей с ограниченными возможностями
- Система автоматизации наружного освещения
- Термоладонь – прибор автоматического измерения температуры тела на входе в учреждение
- «Умный» свет
- Система автоматического открывания крышки и контроль заполнения урны для мусора
- Генератор дома. Двигатель Стирлинга
- Создание Портативного Автоматического Бесконтактного Измерителя Температуры (ПАБИТ-20)
- Разработка экзоруки
- Разработка мобильной игры «ХимикУМ»
- Волонтёрская команда «Тим-ка»
- Автоматизированная парковка
- Создание сельскохозяйственного квадрокоптера «Агро 500»
- Разработка интерактивного сайта для подготовки к олимпиадам по математике
- Создание сайта с нейросетью «CatMe»
- Программа «MY SMART BUDGET» для контроля личного бюджета
- Разработка программного обеспечения для построения трассы искусственного спутника Земли
- Rogmathia – компьютерная roguelike-игра для изучения точных наук в развлекательной форме
- Безопасный обмен сообщениями: мессенджер с шифрованием
- Автоматизированная система дезинфекции воздуха, бесконтактного измерения температуры и обработки рук для образовательных организаций
- Разработка чат-бота для подготовки к ЕГЭ по профильной математике
- Информационный портал «Мир стереометрии»
- Благотворительность online
- Спортивные объекты ЮАО Москвы (Волейбол)
- Создание игры на Unity
- Разработка лидара без движущихся частей под ROS для улучшения алгоритмов движения БПЛА в замкнутом пространстве
- Карта в дополненной реальности
- Умная таблетница с функциями индикации времени приёма таблеток и звукового оповещения
- Медицинский многофункциональный универсальный матрас (эффективный, в том числе для больных COVID-19)
- Шкатулка с кодовым замком
- AR-технологии в школьных учебниках и книгах
- KEINN ONE:1 беспилотный электромобиль
- Бактериальный биореактор
- Повторяшка – тренажер для развития памяти и внимания для самых маленьких
- Мобильное приложение для распознавания Е-добавок eFinder
- Проектирование мобильного интернет-справочника «КакВыжить»
- Модель автоматической системы «Безопасное жильё»
- Чат-бот «Библиотека Ньютона»
- Разработка кроссплатформенной интеллектуальной обучающей игры «АБВГДейка» для привития учащимся начальной школы знаний, понятий и навыков в сфере правописания
- Создание мобильного приложения «Пятиминутка: тренажёр по физике» для платформы Android
- 3D-модель манекена с изменяемыми параметрами
- Стенд для ниток DorTak
- Централизованная, масштабируемая, кроссплатформенная и многопользовательская система "Интернет вещей"
- FedChat: чат с асимметричным шифрованием
- Создание информационного портала для новичков и любителей горных лыж – Properski.ru
- Учебно-игровое пособие «Искатель»
- Автоматический дозатор лекарств
- Настольная развивающая игра «Контур»
- Школа будущего. Современный кабинет математики
- Модель многофункциональной инновационной школы
- Классификация звёзд на языке программирования Python
- Синтез и исследование противогрибковых свойств наночастиц ZnO с этосомным покрытием
- Шифрование файлов на Python гибридным протоколом
- Создание мобильного приложения для помощи в ведении домашнего хозяйства
- Виртуальный музей
- Модель межпланетного космического корабля с оптимальным двигателем
- Моделирование коллекции наград Великой Отечественной войны
- Использование 3D-моделей для создания спортивных аксессуаров
- Создание 3D-модели рукоятки для классического спортивного (олимпийского) лука
- 3D-модель электровиолончели по индивидуальному дизайну
- Кубические иллюзии
- Создание 3D-модели автомобиля для изучения аэродинамических характеристик с использованием программ Autodesk Fusion 360 и SolidWorks 2020
- Наушники для слабослышащих с использованием технологий 3D-моделирования и печати
- Технологии дополненной реальности на службе у музея космонавтики
- Методы получения новых материалов на основе пероксидных соединений олова
- «Арка Шухова»: разработка конструкции по мотивам инженерных решений В. Г. Шухова
- Новый полимерный материал и катализатор для его получения
- Исследование норм потребления средств для стирки
- Чат-бот для решения задач по физике по теме «Кинематика»
- Средство улучшенного распределения контейнеризации в облаке In.Cloud
- Создание трёхмерной модели рельефа (Крым)
- Приложение «Voice». Голос каждого будет услышан
- Создание 3D-модели жилого дома и программы расчёта материалов для его строительства
- Онлайн-мониторинг состояния домашних питомцев по параметрам физической активности
- Система дистанционного контроля обеспечения питьевого режима в школьном корпусе
- Анатомическая накладка на автомобильное сиденье
- Определение применимости лазерных и аддитивных технологий при изготовлении музыкальных инструментов
- Пресс для утилизации алюминиевых банок с пневмоприводом
- ПДД VR
- Приложение для Android по изучению неправильных глаголов английского языка
- Синтез гликопроизводного 1-аминокси-3-аминопропана как потенциального противоопухолевого препарата
- Бифункциональные платформы на основе производных дифенилфосфина для синтеза комплексов золота(I)
- Сравнение бактерий кисломолочных продуктов с пробиотиками, содержащимися в лекарственных препаратах
- Биметаллические тиоцианатные комплексы лантана: синтез и свойства
- Синтез гетерогенного катализатора для селективного получения альдегидов С5
- Усилитель мобильного интернета
- Создание автоматической системы капельного орошения для комнатных растений
- Создание прототипа портативной дозарядочной станции для магазинов автоматических винтовок
- Ионолёт
- Зарядная станция на базе Элемента Пельтье
- Прототип промышленного робота-манипулятора
- Металлополиуретановый гусеничный движитель транспортёра для перемещения тяжеловесных грузов по лестничным маршам
- Рибофлавин: качественный и количественный анализ препаратов и продуктов питания. Измерение спектра поглощения вещества
- Получение наночастиц серебра и их влияние на структуру мезофаз жидкокристаллических алкилоксибензойных кислот
- Сравнительный анализ антибактериальной активности ряда пряных растений (аира, куркумы и имбиря) и оценка перспектив их использования в медицине
- Очистка диглицерида – структурного компонента противоопухолевых катионных глицеролипидов
- Спектральный анализ
- Исследование защитных свойств линз солнцезащитных очков от ультрафиолетового излучения
- Изучение влажности воздуха вблизи различных объектов
- Лазерная бас-гитара
- Эволюционная трансформация лобзика
- Система позиционирования
- Аналоговый и Hi-Fi усилители. Сравнение и анализ характеристик
- Многофункциональная погодная станция
- Трансформатор Тесла. Беспроводная передача электричества и использование резонансных электромагнитных стоячих волн в катушках
- Модульные конвейерные линии
- Транспортная система мегаполиса на примере возможного решения проблем сообщения Москвы и близлежащего города Подмосковья – Видное
- Мини-станция по сортировке строительного мусора
- Модуль для поиска решения задачи N×N в теории игр
- Аэродинамическая труба для моделей
- Разработка онлайн-платформы по бартерным обменам на основе технологии смарт-контрактов
- Основная мысль текста
- Проектирование элементов городского электротранспорта. Электромотоцикл
- Разработка чат-бота «Ромашка»
- Решение базовых задач по физике на термодинамику с помощью программы на платформе PascalABC.net
- Применение технологии блокчейн для продвинутого отслеживания посылок
- База данных олимпиадных и усложнённых задач по точным наукам
- Применение технологии Blockchain для отслеживания состояния пациента
- Онлайн-библиотека для студентов и школьников
- Разработка и внедрение в производство полимерных упругих шарниров, применяемых для аппаратов на коленный и локтевой суставы для детей с нарушениями опорно-двигательного аппарата (в том числе и при ДЦП)
- Светодиодный журнальный стол
- Мультиполигон
- Электронная библиотека для школьных читателей
- Разработка С-компилятора для 16-разрядной виртуальной машины
- Интерактивный сайт, посвящённый волейболу
- Разработка модели инновационной парты
- Дизайн внутреннего дворика корпуса МИРЭА
- Разработка виртуальной кухни с использованием технологий виртуальной реальности
- Лазерный станок с числовым управлением
- Интегрирование сушильной камеры филамента в 3D-принтер Picaso Designer X Pro
- PowerWords: приложение для изучения сложных тем английского языка
- Дизайн внутреннего дворика корпуса В МИРЭА
- Проект моста для пешеходов и велосипедного транспорта в центре Копенгагена
- Стол-трансформер
- Дизайн-проект школы искусств
- «Азбука Шухова «SET OF 33»
- Учебно-познавательная тропа «Ландшафты родного края»
- Игрушка «Детская площадка»
- Специальное рабочее место
- Применение 3D-технологий для визуализации образовательного процесса на примере шахмат и математических фигур
- Разработка 3D-модели Золотого моста
- Виртуально-реальный или комбинированный музей
- Концепция Smart@EPower – социальная сеть потребителей электроэнергии в «Умном городе»
- Синтез ацетона из изопропанола
- Создание автономной энергетической установки с использованием полупроводникового элемента
- Исследование влияния кофеина на рост и развитие бактерий
- Выбор оптимальной схемы армирования и технологии изготовления деталей беспилотного летательного аппарата из композиционных материалов
- Автоматизированный поворотный предметный столик для поляризационного микроскопа
- Система безопасности «Чистый воздух»
- ReКуп
- Постройка судна на беспилотном управлении
- Аэротакси
- Муниципальный многофункциональный робот
- Реновация школ серии МЮ
- Ячейки для хранения личных вещей
- Лазерные технологии в современной школе
- Разработка модели подвижного медицинского комплекса на базе трансформируемого полуприцепа
- Разработка айдентики детского клуба спортивных танцев Let's Dance
- Дизайн, архитектура и современные технологии. Трансформация: арт-объект – VR-музей
- Организация мероприятий по ресурсосбережению
- Разработка интеллектуализированной системы поддержки принятия решений обеспечения безопасности NannyNet
- Игровой алгоритмический тренажёр для младших школьников – робот «Шагайка»
- Регулирование освещённости в комнате с помощью фоторезистора и потенциометра
- Интеллектуальная система управления оконными жалюзи
- Карманный кардиомонитор
- Изучение эффективности антибактериальных медицинских средств
- Решение задачи о брахистохроне опытным путём
- Автоматическая кормушка для кота
- Изучение антибиотических свойств препарата «Ротокан» и его компонентов
- Создание простых механизмов на основе принципов гидравлики
- Разработка упрощённой схемы определения допинга в лекарственных препаратах
- Получение обратной эмульсии с инкапсулированным ниацинамидом
- Синтез бутаналя и его анализ
- Разработка нового композитного материала для использования в авиастроении
- Идентификация и количественное определение 6-аминокапроновой кислоты в лекарственных препаратах
- Разработка упаковки пищевых продуктов для пролонгации их сроков хранения
- Влияние легирующих элементов и термической обработки на структуру и свойства сплавов на основе алюминия, используемых в промышленности
- Агенты для фотодинамической терапии на основе металлоорганических соединений
- Определение критической температуры диоксида углерода методом электронного парамагнитного резонанса
- Исследование эксплуатационных свойств фильтрующих картриджей
- Металл-полимерные композитные мембраны для выделения водорода из газовых смесей
- Микробный топливный элемент
- Получение экстракта слизи улиток и его использование для внеклеточного матрикса
- Синтез аденинового мономера пептидно-нуклеиновых кислот на основе L-глутаминовой кислоты с циклогексильной защитой и оценки его выхода
- Нелинейно-оптические лимитеры для защиты органов зрения от высокомощного лазерного излучения
- Проектирование и разработка бионического протеза ноги
- Сравнение эффективности катушек индуктивности разных форм для беспроводной передачи энергии имплантируемым медицинским устройствам
- Создание 3D-модели школы
- Гроубокс
- Приложение для обучения правилам дорожного движения (ПДД)
- Разработка виртуального тренажёра для развития навыков вождения автомобиля с использованием технологий виртуальной реальности
- Induction Heater / Индукционный нагреватель
- Robotic Hand Роботизированная рука
- Master Bin 20.2.0: a Smart Waste Collection and Sorting System / Интеллектуальная система сбора и сортировки использованной тары «Master Bin 20.2.0»
- Сигнализация
- Разработка прототипа серийной модели светоуправляемой колесной платформы
- Прибор для контроля уровня pH водной среды в аквапонической установке
- Прототип энергоэффективного индикатора на микроконтроллере ESP32 и полевых транзисторах
- Создание устройства для исследования подводных источников газа (сипов)
- Использование лазера для измерения концентрации взвешенных частиц в воздухе
- Умное медицинское устройство (УМУ) для предварительной постановки диагноза с применением микроконтроллера Arduino
- Световой будильник
- Мультифункциональный шлюз управления
- Создание манипулятора с цветовой идентификацией предмета
- 3D-«крестики-нолики» на Arduino
- Многофункциональная роботизированная станция для занятий рисованием
- Прибор для измерения электромагнитного излучения в быту
- Столик с электронным управлением для фотографирования минералов
- Регулирование влажности воздуха в комнате
- Устройство зарядки с элементом Пельтье
- Проектирование корпуса для обучающей интерактивной карты звёздного неба
- Создание конструкции пульсирующего сердца при помощи микроконтроллера ATtiny2313
- Создание теплицы с автоматическим поливом растений
- Исследование зависимости передаточных и выходных характеристик полевых транзисторов на основе органических кристаллов-полупроводников DH-P-TTA от материала электродов
- CMC (Clever Morning Closet)
- Браслет управления автомобилем
- Современная копилка
- Спасательный маячок
- Электронный арбитр для интеллектуальных игр
- Аппаратно-программный комплекс термомеханической сборки печатных плат
- Прототип пожарной сигнализации
- Ошейник, облегчающий поиск потерявшегося животного
- Разработка периферийного устройства, которое будет предупреждать появление проблем со зрением при роботе с компьютером
- Музыкальная катушка Тесла
- Проектирование и моделирование светодиодных созвездий
- Индуктивный датчик для измерения импульсных токов с амплитудными значениями порядка 1-2кА
- Автоматическая теплица для выращивания специй
- «Умный» зонт
- Сортировка пластика
- Полуавтономная солнечная панель
- Автоматизация кастрюли
- Разработка и создание программируемого робота, дозирующего и раздающего жидкости
- Портативная сигнализация для кошельков и телефонов
- Создание автоматизированной технологической домашней теплицы
- Кроссплатформенный проигрыватель на Python
- Беспилотный шнекоход
- Канатная дорога как промышленный транспорт в условиях Луны
- Изготовление прототипа катера с ДВС
- Разработка концепта транспортного средства для исследования Арктических зон
- Эндуро мотоцикл
- Гусеничная платформа высокой проходимости
- Влияние резонатора на работу двухтактного двигателя
- Бионический квадрокоптер "nonopus"
- Разработка и создание автоматизированного робота для сортировки мусора
- Навигатор по вузам Москвы
- «Linkage»
- Система оповещения о лесных пожарах
- Приюты для животных
- Методы реализации устройств «умного» дома
- Прогнозирование технологических параметров процессов установки первичной переработки нефти с использованием современных программных средств нейросетевого моделирования (Deductor Studio Academic)
- Программа на языке Python для создания трасс по классической скорости в спортивном скалолазании
- Разработка мессенджера для школьной коммуникации
- Новое применение RFID- технологии в метро
- Разработка приложения дополненной реальности для музея
- Разработка сайта о ветеранах Великой Отечественной войны
- Визуализатор G-кода
- Программа для автоматизации работы с интерфейсом персонального компьютера
- Индивидуальный подбор технических олимпиад для учащихся 8–11 классов
- Универсальный модуль для космических исследований
- Определение колеи и базы автотранспортного средства в криминалистике
- Создание ассистивного устройства для слепых и слабовидящих людей
- Компьютерная система обобщающей обработки результатов тестирования
- IoT-control of the indoor plants and their watering / IoT-контроль и полив комнатных растений
- Устройство помощи в ориентировании слабовидящих людей
- Разработка сайта приюта для домашних животных
- Централизованная сеть для удалённого коллективного ведения базы данных домашних заданий школьника
- Разработка сайта-энциклопедии по математике
- Конструирование плоттера
- Идентификация личности по цветовому ключу при помощи камеры
- Применение технологий «блокчейн» в сфере оказания услуг горнолыжных комплексов
- Методы симметричного шифрования
- Разработка сервиса автоматического сбора, фильтрации и анализа новостей о ДТП, произошедших в РФ
- Реализация алгоритма PageRank и его тестирование на реальных данных
- Разработка рекомендательной системы по подбору музыки
- Многофункциональная система шифрования «MES»
- Мобильное приложение AutoTourist
- Создание макета трансформируемого модуля космической станции
- Сравнение методов аппроксимации данных путём минимизации функций невязки различных видов
- Создание приложения, предназначенного для нахождения мест по утилизации мусора
- Инструментальная платформа для разработки специализированных вычислительных систем
- Разработка расширения для браузера, основанного на системе Blockchain, в целях решения проблем безопасности хранения своих и чужих паролей и аккаунтов в интернете
- Мобильное приложение голосовой помощник «ЧАЙКА»
- Игра «WIRES», обучающая основам алгоритмизации
- Развивающее приложение для детей «Умножайка»
- Конструкция «Вертикальный сад» с автоматизированным поливом для поддержания экологии школьной среды
- Чат-бот для решения квадратных уравнений
- Генеративное проектирование робота-манипулятора
- Разработка математического интернет-тренажёра по устному счёту
- Создание интерактивного квеста «The FORTune of ROSS» как ключевого мотивационного инструмента в изучении истории и культуры России и США
- Создание нейронной сети для определения состояния сна человека
- Онлайн-платформа MathBattle
- Программа – визуализатор силовых линий поля
- Система автоматизированного контроля соблюдения питьевого режима
- Система визуализации и контроля передвижения
- Создание игры-тренажёра для решения задач физико-математического цикла
- Автоматизация подготовки заготовок печатных плат
- Комплексные соединения хлоридов европия и гадолиния с салициловой кислотой: синтез и применение
- Подбор оптимального флюорофора для использования в нейрохирургии с флуоресцентной интраоперационной визуализацией
- Синтез субклеточно-нацеленных фотосенстибилизаторов
- Разработка состава и технологии получения шипучей таблетки с экстрактом черники
- Разработка аналогового действующего вещества препаратов для лечения и профилактики железодефицитной анемии
- Синтез двойных ортофосфатов и ортованадатов гадолиния и исследование их свойств
- Наноматериал для улучшения качества родниковой воды
- Оптимизация методов выделения бактериопурпуринов
- Миметик глицина на основе производного гераниола
- Military drone – «Shooter»
- Новая аэродинамическая компоновка летательного аппарата
- Ультразвуковой контроль скорости внутренней коррозии стальных ёмкостей и трубопроводов
- Исследование электромагнитной индукции на примере создания металлодетектора
- Адаптивная система экономии электроэнергии
- Применение современных датчиков и средств сбора данных при демонстрации физических законов
- Винт вертолета из углепластика
- Система позиционирования и навигации для «Умного города»
- Исследование бумаги А4 на прочность
- Зонд для сбора данных о явлении пробоя на убегающих электронах
- Исследование и инновационное практическое применение сплава с эффектом памяти формы
- Синтез липида-хелпера – компонента катионных липосом для генной терапии
- Создание косметических средств на основе экстракта алоэ вера и на основе аллантоина
- Создание флуоресцентного зонда для изучения метаболизма метформина
- Синтез и подбор оптимальных условий очистки Sn-комплексов лизина
- Выбор растворителей для реакции получения эпихлоргидрина на основе исследования их свойств
- Индикатор срока годности
- Исследование примесей в составе зарубежного препарата и его российского аналога
- Синтез аналога радиофармпрепаратов на основе металла галлия и хелатора тетракарбоновой кислоты (DOTA) с потенциальной визуализирующей и противоопухолевой активностью
- Влияние буферных агентов на процесс меднения
- Оптимизация процессов синтеза комплекса гадопентетовой кислоты, используемого в качестве контрастного диагностического препарата для магнитно-резонансной томографии
- Сорбционная очистка сточных вод гальванического производства от смесей тяжёлых металлов и органических компонентов
- Разработка джема с добавлением хлорофилла
- Разработка сорбента для аффинной хроматографии на основе пептидомиметиков
- Получение натурального корригента запаха для дезинфектанта в форме спрея
- Суперконденсатор и области его применения
- Разработка программного решения для определения угла поворота магнитометра
- Изучение природных фотонных кристаллов методами современной микроскопии
- Исследование влияния вакуума на процессы преобразования веществ
- Исследование предельных характеристик MEMS-гироскопа в реальных условиях для осуществления задач навигации и стабилизации объектов в пространстве
- Технико-экономическая оптимизация параметров бытового воздухоочистителя
- Система синхронизации на основе механического модулятора оптического сигнала
- Визуализация магнитного поля
- Трансформатор Теслы как атрибут школьной лаборатории, наглядно демонстрирующий свойства электрического тока
- Исследование длительного переохлаждения водных суспензий, запертых под углеводородной плёнкой
- Водный исследовательский комплекс «ВИК-2»
- Создание модели имплантируемого кардиостимулятора с беспроводным энергообеспечением
- Эффективность дезинфицирующих средств бытовой химии
- Инкубатор для эксперимента
- Проектирование и разработка автоматизированной системы отслеживания состояния людей с сердечно-сосудистыми заболеваниями на основе дистанционного измерения ритма сердца
- Создание осязаемой 3D-реконструкции Третьего Кавалерского корпуса Царицынского дворцово-паркового ансамбля
- Система контроля воды в кулерах
- Система помощи при эвакуации
- Комплексная система безопасности мотоцикла
- Фотонная структура для управления электромагнитным излучением
- Возможности бесконтактной передачи вращения
- Разработка прототипа мобильной роботизированной платформы для помощи в сельском хозяйстве «Siberian tiger»
- Сонификация сложных физических процессов как средство отображения информации в тифлопедагогике
- Определение ионного состава водных растворов с помощью лазерной спектроскопии комбинационного рассеяния и метода искусственных нейронных сетей
- Создание онлайн-музея «Великая Победа»
- Психоэмоциональный тренажёр, восстанавливающий мимику у людей, перенёсших инсульт
- Мобильное приложение «Дневник самоконтроля»
- Проектирование мобильного интернет-справочника «КакВыжить»
- Интеллектуальная игра
- Обработка изображений с помощью языка программирования Python 3.7
- Проектирование размещения мебели в дополненной реальности
- Разработка приложения с использованием дополненной реальности для визуализации приготовления блюда по заданному рецепту
- Приложение дополненной реальности для визуализации географических карт
- Приложение дополненной реальности для визуализации содержания ячеек хранения систем складского учёта
- Метеостанция
- Улучшение работы системы светофоров на перекрёстке
- Глубокая модернизация 3D-принтера Cubex trio компании 3DSystems
- Интеллектуальная система дистанционного полива комнатных растений
- Система автоматизированного учёта сбора пластиковых крышечек
- Автоматизация грибной фермы
- Разработка «умного» коврика на Arduino
- Stereomix
- Робот на самоуправлении
- Шаг на пути к антропоморфным роботам
- Проблема загрязнения окружающей среды бытовыми отходами. Моделирование удобной «корзины» для раздельного сбора мусора
- Разработка мобильной платформы под управлением голосового интерфейса для осуществления работ в труднодоступных местах
- Детская площадка в стиле Minecraft
- Устройство мониторинга местности
- Дистанционно управляемый мобильный робот общего назначения (ДУМРОН)
- Исследование погрешностей в работе квадрокоптера в разностно-дальномерном режиме позиционирования TDoA2
- Робот удалённого присутствия
- Акцентирующее освещение в сценографии
- Макет «Высота «Погранзнак»
- Робот-кошка
- Радиоуправляемое судно для очистки водоёмов
- BIM-технологии в строительстве
- Выявление методов нейтрализации несанкционированных беспилотных летательных аппаратов
- Практическое применение компьютерного зрения
- Проект «Арт-объекты в стиле графики А. С. Пушкина "У Лукоморья"»
- Пилотируемый трикоптер TRIFLY, выполненный из сверхлёгких композиционных материалов
- Дизайн универсальной деки для лонгборда BAUBOARD, выполненной из сверхлёгких композиционных материалов
- Создание мини-трактора
- Разработка и конструирование двигателя внутреннего сгорания с использованием 3D-принтера
- Сценография. Создание декораций к школьному спектаклю «Король Лев»
- Применение суспензии тонкомолотого перлита для повышения прочности цементного камня
- Программа строительства оптимального по цене частного дома
- Лодка из композитных материалов
- Диодно-лазерный станок
- «Умный» светильник
- Создание элемента интерьера с помощью средств цифрового производства
- Хранение медикаментов для людей с хроническими заболеваниями
- GreenBox («умная» теплица)
- Робот для автоматизированной сортировки мусора
- Образовательное приложение с дополненной реальностью «Interactive road signs»
- Виртуальная химическая лаборатория
- Нейронная сеть. Умный староста
- Использование панелей в качестве альтернативного источника энергии в школе
- Распознавание лиц в школе
- Приложение-энциклопедия экзотических фруктов
- Создание 3D-модели радиатора и её применение в процессе изготовления пульта проверки
- Гидроэлектростанция турбинного типа
- «Радиопломба» – цифровое устройство, ликвидирующее хищения электроэнергии
- Конструирование деталей и проектирование электронной схемы ветроэлектрогенератора
- Образовательный стенд «Бионический протез»
- Экскурсионный 3D-маршрут по корпусу института тонких химических технологий Российского технологического университета МИРЭА с использованием VR-технологии
- Разработка тактильной карты для слабовидящих детей
- Флейта из углепластика
- Проект визуализации рассказа Р. Бредбери «Всё лето в один день» с использованием технологий виртуальной реальности
- Моделирование: ферментация чеснока в домашних условиях
- Разработка и создание прототипа устройства, помогающего людям с дефектами зрения определять сигнал светофора
- Мышка для людей с ограниченной подвижностью рук
- Устройство для мониторинга температуры тела у животных
- Автоматическая система управления светом (АСУС)
- Химия – просто! История создания одной компьютерной игры
- Робот-экскурсовод
- Модель бьющегося сердца
- «Умная» система пневмоочистки IT-устройств
- Разработка смарт-контракта для осуществления торговых сделок
- Приложение для детей младшего и среднего школьного возраста «Звук и Слово»
- Устройство контроля уровня мусора в контейнере
- Автоматизированное освещение в непроходных помещениях
- «Компьютерное зрение». Система доступа на объект посредством распознавания лица
- Проектирование персонального 3D-принтера
- Создание декораций для спектакля на основе чертежей, рисунков, 3D-моделирования по повести-сказке Эрнеста Теодора Амадея Гофмана «Щелкунчик и Мышиный король»
- Использование VR-технологий при проектировании городского парка
- Разработка виртуального проекта будущей квартиры с использованием технологий виртуальной реальности
- Архитектурная визуализация и VR-технологии
- Мобильное приложение «Школьная лаборатория в дополненной реальности»
- Инновационный кабинет информатики
- «Мы смотрим на звёзды, или звёзды смотрят на нас?»
- Разработка образовательного приложения по географии с использованием AR-технологий для инклюзивного образования
- Приложения дополненной реальности для образования
- Арт-объекты на Arduino для площадок Москвы
- Макет ветрогенератора с вертикальной осью
- Архитектура метаболизма. Модульные системы
- Невероятная эволюция изоморфов (применение генетических алгоритмов в программировании)
- Разработка компьютерной игры Cube Rush в Unity
- Программа для шифрования «Securnote» (информационная безопасность)
- Робот «ГОР» для дистанционного осуществления погрузочно-разгрузочных работ
- Разработка метода выделения белка из растительных продуктов
- Разработка и создание приложения для калибровки камеры под квадрокоптер «Клевер»
- Разработка метода выделения пектина и фуранокумаринов из борщевика Сосновского
- Создание сопел жидкостных ракетных двигателей
- «Умная» теплица
- Получение поликатионного амфифила для создания липосомальных структур в генной терапии
- Создание системы доставки лекарств на основе магнитных наночастиц
- Разработка автономного беспилотного летательного аппарата без использования систем GPS и ГЛОНАСС
- Система распознавания лиц в школе
- Средство передвижения для людей с ограниченными возможностями с функцией мониторинга сердечно-сосудистой системы и дистанционным управлением
- Создание виртуальной экскурсии по Музею истории вычислительной техники в «Школе № 1530 «Школа Ломоносова»
- Автоматизированное управление микроклиматом теплицы для выращивания редких экзотических и лечебных растений
- Создание приложения под Windows для управления PTZ-камерой
- Игра как эффективный метод изучения Красной книги Московской области
- Разработка электронного устройства «Умный турник» на основе Arduino
- Разработка лабораторного стенда для исследования ПИД-регулятора
- Умное стекло
- Автоматизация технологического процесса подготовки заготовок печатных плат
- Управляемый комплекс для имитации дневного освещения аквариума
- Разработка и постройка БПЛА мультироторного типа для нанесения граффити на вертикальные поверхности
- Создание системы распознавания заболеваний растений с использованием машинного зрения и БПЛА
- Внедрение магнитной левитации в подвеску автомобиля
- 3D-расчёты магнитной системы
- Разработка сервиса для организации поисково-спасательных операций Rescue Map
- Изучение влияния антимикробных пептидов на антибиотики при их совместном применении
- Модель робота-сортировщика
- Устройство для кипячения воды, работающее через USB на эффекте Пельтье
- Создание мембраны для актуатора
- Методический конструктор для слепых и слабовидящих детей «Сириус»
- Создание и исследование коронно-разрядного двигателя
- Универсальная автономная установка генерирования электроэнергии
- Робототехнические системы в современных технологиях
- Создание интернет-ресурса «Здоровый сон»
- Увлекательная система сбора использованных батареек
- Использование солнечных панелей в качестве альтернативного источника энергии в школе
- Модель-конструктор к урокам биологии в школе «Сравнение растительной и животной клеток»
- Определение подлинности лекарственных средств на Российском рынке фармацевтики на примере района Куркино
- Электровелосипед
- ARmuseum
- Взаимодействие жидкокристаллических алкилоксибензойных кислот с растворителями
- Фотокатализаторы на основе диоксида титана: получение и применение
- Комплексные соединения РЗЭ с фосфоновыми кислотами: синтез и их применение
- Технология дополненной реальности AR в образовании «Растительная и животная клетка»
- Разработка облучательной установки для повышения продуктивности процесса фотосинтеза
- Метаматериалы
- Быстрее ветра, или Может ли исследование сопротивления воздуха помочь создать модель нового транспортного средства
- Светодиодный куб 8˟8˟8
- Наглядное пособие для демонстрации явления самоиндукции
- Мобильная робототехническая система для трёхмерного сканирования
- Модификация алюминиевого сплава АД0 путём придания его поверхности супергидрофобных свойств
- Синтез и выделение ароматизаторов. Исследование возможности их применения при изготовлении мыла
- Сокращение тепловых потерь в системе ХВС и ГВС
- УФ-очистка воды
- Ультразвук и его влияние на живые организмы на примере дрожжевых клеток
- Разработка супергидрофобных покрытий на поверхности магниевого сплава МА8
- Связывание катионных препаратов с различными биологическими лигандами
- Влияние выбора растворителя на продукт взаимодействия цинка с йодом
- Функционирующая модель модуля космической станции с радиоуправляемыми бортовыми системами жизнеобеспечения
- Беспроводная Bluetooth-колонка с автономным источником питания
- Медицинский тренажёр-симулятор для обучения мануальным навыкам эндовидеохирургии
- Интерактивный программируемый театр
- Разработка технологии получения биоразлагаемых амфифильных блок-сополимеров
- Автоматическая кормушка для питомца
- Умная бионическая рука
- Энергосберегающая система контроля и управления «Умный дом»
- Мехатронный модуль «Контрольно-сортировочный автомат»
- Металлоискатель
- Модель двигателя Стирлинга
- Ветер: бесплатная энергия вокруг нас
- Декоративный увлажнитель воздуха
- Виброжилет
- Автоматизация полива: качество выше при меньших издержках
- Создание препарата комплексного действия на основе производного хлорофилла
- Моделирование поведения металлосодержащих препаратов для терапии и диагностики рака в человеческой сыворотке
- Интеллектуальный комплекс систем оповещения с применением GSM-модуля
- Система автоматизированного контроля врача-анестезиолога
- Разработка комплекса программного обеспечения для образовательных организаций
- Нейротехнологии и высокотехнологичные протезы. Установка для изучения мозговых сигналов и мышечных реакций
- Иммобилизованный фотопереключаемый флуоресцентный белок как основа для носителя информации
- Стенд-скоростемер (универсальный разгонный стенд для измерения скорости кордовых моделей автомобилей)
- Электростатический напылитель
- «Разработка устройства для быстрой очистки школьной доски «FastClean»
- Создание защиты из композитных материалов
- Исследование физико-химических свойств смеси ацетонитрил – циклогексанон и оценка возможности её разделения с использованием ректификации
- Ультразвуковой метод ориентации в пространстве с применением компьютерного зрения для слепых и слабовидящих людей
- Автоматическая линия производства вязких лекарственных препаратов
- Разработка тренажера реакции
- Система для терморегулирования одежды рабочих в условиях Крайнего Севера
- Программируемый аудиозамо́к
- Макет 1 : 87
- Умный увлажнитель воздуха
- Система автоматизированной оценки качества водительских навыков
- Разработка программного обеспечения системы автоматического управления конвейерами машин типа СЗ
- Умный рюкзак (Smart backpack)
- Воздействие лазера постоянного излучения с длиной волны 532 нм на старую бумагу
- Система мониторинга нарушений ПДД детьми и подростками
- Многофункциональный контейнер для перевозки растений
- Персональный летательный аппарат
- Переработка пластиковых отходов в условиях малого бизнеса
- Инновационный вид транспорта, представляющий собой гибрид монорельса и канатной дороги
- Разработка модели автоматической системы обеспечения непотопляемости корабля
- Разработка концепта транспортного средства для исследования арктических зон
- Разработка базового модуля сети контроля окружающей среды
- Устройство борьбы с засыпанием водителей «Антисон» в процессе вождения
- Модульная многофункциональная космическая система
- Системы рекуперации в гибридном автомобиле
- Авторотация как эффективный способ спасения метеорологических ракет
- Разработка станка для заточки вольфрамовых игл
- Создание прибора для определения параметров микроклимата
- Техническое средство робот PinGo для реабилитации детей с ограниченными возможностями
- Макет инновационной школьной парты
- Создание живых обоев на окнах
- Дизайн-проект IT-полигона на базе ГБОУ Школы № 1532
- Метод оценки устойчивости склонов заданного участка местности
- Программно-аппаратный комплекс предупреждения возникновения пожаров на открытом пространстве
- Робот, собирающий кубик Рубика
- Космическая станция
- Карданов подвес с электроприводом, дистанционным управлением и компьютерной визуализацией положения макета в пространстве
- Полётный контроллер для мультироторных систем
- Модель устройства помощи при экстренном торможении
- Модель радио А.С. Попова на уроках физики и во внеурочной деятельности
- Магнитный бестопливный генератор энергии
- Волновой маятник: разработка компьютерной и механической модели маятника Чеботаева
- Мини-гидроэлектростанция для многоквартирного дома
- Судно на воздушной подушке для очистки водоёмов
- Моделирование переноса пластиковых объектов в вихревых течениях
- Автономный конденсатор − накопитель воды, работающий на принципах законов физики в условиях жарких засушливых регионов
- Исследование влияния топологии подложки на формирование и рост островковых тонких плёнок меди
- SmartTBox
- Универсальный робот-транспортёр
- Беспилотное транспортное средство
- Добыча электроэнергии из воды
- Исследование и визуализация точки бифуркации
- Перспективы золотоносности Сочинского района. Научные разработки диагностики минерального состава сульфидных руд
- Эффективность ветрогенераторов с различными конструкциями роторов
- Применение высокодетальных данных спутниковой съёмки для предотвращения гибели гренландских тюленей в акватории Белого моря
- Электронный живописец
- Робот - «трубочист»
- Согревающий жилет на химических источниках тепла
- Изготовление деталей для станка UNIMAT
- Разработка прикладного программного обеспечения для тестирования экспериментальных структур сверхпроводник-изолятор-сверхпроводник (SIS-переходов)
- Мобильная система видеосъемки «Паук»
- Протезирование точной копии кисти руки человека на основе результатов трёхмерного сканирования
- Тактильные лабиринты Москвы
- Визуализация школьной формы в электронном формате
- Гидрологический цикл
- Разработка и создание лазера на молекулярном азоте с поперечным разрядом
- Ионофон − «поющая» плазма
- Моделирование и анализ развития градостроительного планирования территории мегаполиса с помощью технологий виртуальной реальности и космического мониторинга
- Симулятор «Пожарный»
- SmartCage. «Умная» клетка для домашних грызунов
- «Умная» крыша» с использованием альтернативных источников энергии и применением микроконтроллера ARDUINO IDE
- Универсальная химическая 3D-модель молекулы и атома
- Симулятор «Граффити»
- Нейронная сеть для обнаружения DGA
- Разработка Android-приложения для автоматизированной проверки устной части ЕГЭ по английскому
- Тактильный набор для построения блок-схем алгоритмов
- Создание мобильного ANDROID-приложения для дистанционного управления роботом входящего в базовый комплект образовательного робототехнического модуля «ТЕХНОЛАБ – базовый уровень»
- Разработка компьютерной игры «LONER» на Unity
- Применение технологии Blockchain для оптимизации работы баз данных спортсменов
- Построение сети организации или маленького офиса
- Telegram news bot на «Python»
- Модульное покрытие-трансформер
- Разработка ботов при помощи Discord API
- Игра для развития устного счёта
- Разработка программно-аппаратного комплекса по отслеживанию посещения учащихся
- «Умная» теплица
- Применение технологии Блокчейн в сфере предоставления гарантий на товары
- Создание интернет-ресурса «Городские квесты»
- Система контроля безопасного для зрения детей использования компьютера
- Управление ВЧ-генератором с помощью программных средств LabVIEW
- Онлайн чат-бот
- Создание химического калькулятора
- Мобильное приложение «Weather Assistant»
- Интернет-ресурс «РУКА ПОМОЩИ» для начинающих пользователей старшего поколения
- Компьютерная программа в виде игры для обучения будущих программистов
- Модульная платформа для разработки высокопроизводительных встраиваемых систем на базе программируемых логических интегральных схем
- Создание интерактивного квеста по химии
- Применение технологии 3D-моделирования в реальной жизни
- Свёрточные нейронные сети для распознавания дорожных знаков
- Knowledge Land – развивающий портал для детей
- Создание игры в GameMaker Studio
- Разработка сети сайтов, посвящённых путешествиям и описанию стран
- Мобильное приложение - словарь и упражнения для изучения английского языка
- Создание интерактивного введения в курс геометрии
- Влияние температуры и природы катализатора на селективность протекания реакции конденсации кетонов
- 3D-принтер
- Искусственный агент с эмоциональной речью и жестами – прототип человекоподобного робота
- Интеллектуальный пульсоксиметр
- Крылья обратной стреловидности
- Мобильное приложение «Автоматизированный контроль состояния здоровья инсулинозависимых людей»
- Единый портал школьных газет Москвы
- Эпоксидирование аллилхлорида
- Альдольная конденсация пропионового альдегида
- Создание роботов для участия в соревнованиях
- Разработка программы автоматизированного составления расписания в школе на основе генетического алгоритма
- Мобильная роботизированная платформа «Siberian Tiger» для помощи в сельском хозяйстве
- «Умная» вентиляция для умной школы
- Система автоматического полива растений
- Физика супертороидов
- Управление роботом при помощи модуля электромиографии (ЭМГ модуля)
- Автоматизированный полив растений
- Симулятор «Крановщик»
- Дополненная реальность в школьном музее «Тайны русского зодчества»
- Математические закономерности в творчестве Никола Пуссена
- Путешествие в мир дополненной нереальности
- Мебель из паллет
- Решение проблем организации сортировки ТБО в зонах жилой многоэтажной застройки
- Разработка и изготовление «Ленинградского» репродуктора 1941 г.
- Проектирование и разработка базы данных крупных торговых центров Москвы
- Разработка веб-сайта для помощи в выборе профессии «wanttobe.pro»
- Разработка потенциальных агентов для комбинированной терапии на основе комплексов олова и природных хлоринов
- Проектирование приложения для обеспечения эффективной и безопасной работы в сети Интернет
- Разработка приложения для навигации по зданию (университета)
- Создание и изучение свойств липофильного диамина с потенциальной противоопухолевой активностью
- Проектирование приложения поддержки планирования и организации осуществления покупок «WishMaker»
- Проектирование приложения музыкального справочника
- Адаптивная система экономии электроэнергии
- Получение производных бактериохлорофилла для биомедицинского применения
- Интерактивный дизайн в виртуальной реальности
- Порфирины – материал для технологии будущего
- Автономные интерактивные информационные стенды на улицах современного мегаполиса
- Создание игры для развития эмоционального интеллекта
- «Вижу свет, или Исследование качества защиты зрения солнцезащитными очками»
- Разработка сайта Московской детской железной дороги
- Модель электромагнитного поезда
- Система оповещения «SOUNDER»
- Модель мобильного лазерно-гравировального станка для выполнения работ на вертикальных поверхностях
- Извлечение соединений неодима из шлифотходов
- Макет школьного лифта
- Компьютерная игра с элементами обучения
- Технология изготовления радиоуправляемого трицикла
- Акустическая колонка своими руками. Выгодно ли собрать ее самому
- Разработка андроида для изучения взаимодействия роботов с людьми
- Влияние структуры фотосенсибилизаторов на связывание с человеческим сывороточным альбумином
- Анализ уровня экспрессии генов VEGF и его рецепторов KDR / FLT-1 методом ОТ/ПЦР в образцах клеточной РНК из биоптатов пациентов с новообразованиями предстательной железы
- Создание 3D-модели-конструктора «Клетка»
- Логическая игра «Перевозчик, Волк, Коза и Капуста»
- Система спасения при пожаре из многоэтажных строений «Лифт жизни»
- Проектирование приспособления для получения различных сферических и фасонных поверхностей на примере фрезера Makita RP2300FC
- Создание прототипа БПЛА
- Морфометрия мозга
- Проектирование и разработка специального программного обеспечения для устройства мониторинга стресса
- Проектирование и разработка действующей модели мобильного ракетного робототехнического комплекса
- Изучение влияния условий запуска и лётных характеристик бумажных самолётиков на дальность их полёта
- Транспортное средство для экстремального вида спорта. Drift-trike. Постройка и модернизация
- Автоматическая система мониторинга учебного помещения на соответствие нормам СанПиН
- Установка для измерения скорости вращения электродвигателя
- Катионные липосомы – эффективные системы доставки лекарственных препаратов нового поколения
- Устройство для автоматизированного изготовления печатных плат путём фрезерования проводящего рисунка
- Модель роботизированного устройства для токарно-фрезерной обработки деталей
- Умный переход («SMART CROSSWALK»)
- Создание аэросаней-амфибии на дистанционном управлении для доставки спасательных средств потерпевшим на воде
- Создание геоинформационного портала средствами QGIS
- Исследование способов оптимизации нейросетевых вычислений
- Формирование наноструктурированных покрытий методом магнетронного распыления
- Эффективный ветрогенератор
- Поиск пути в топографических условиях
- Биметаллические терефталаты лантанидов как люминесцентные термометры
- Concept Art. Artbook. The Age of Snowbounded
- Прототип модульного умного дома
- Выявление и устранение проблем с освещением на больших территориях
- Гидротермальный синтез корунда и его цветных разновидностей
- Ацетофенон как новый стабилизатор пероксида водорода
- Мобильная солнечная электростанция с системой слежения за солнцем
- Изучение условий конусообразования сыпучих тел
- Автоматизированная касса самообслуживания
- Разработка системы дистанционного управления домом на базе платформы Arduino
- Изменение поверхностного рельефа титанового сплава в плазме высокочастотного индукционного разряда
- Мини уборочная машина
- Создание сканирующего туннельного микроскопа
- Автономная исследовательская платформа для изучения физических свойств окружающей среды
- Робототехническая система нанесения дорожной разметки
- Робот по обслуживанию склада
- Робот-собиратель
- Иллюстрированная книга «Каменный гость» по произведению А. С. Пушкина
- Интеллектуальная система обнаружения пожара
- Организация вертикального сада в интерьере школьного пространства
- Разработка агрегата для проверки герметичности упаковки лекарственных препаратов
- Влияние режима сна на развитие тревожности у подростков
- Ножничный подъёмник
- Создание электробайка EFEB
- Проект 3D-модели навигации по зданию аэровокзального комплекса
- Конструирование велосипеда с электроприводом
- Ветрогенератор
- «Зенит» и веб-камера
- Малые архитектурные формы
- Радиоактивные металлы как средство для терапии и диагностики
- Модульная роботизированная техника для уборки промышленных отходов на территории Заполярья и для планового развития региона
- Преобразование «шаговой» энергии в электрическую и использование её для нужд мегаполиса
- Разработка и изготовление набора деталей для 3D-печати, для изучения робототехники
- Генератор альтернативной энергии
- Робот-уборщик
- Протезирование руки
- Исследование химического состава и физических свойств батареек при различных условиях эксплуатации
- Сборка гальванического элемента и повышающего преобразователя и его использование для изучения электролитической диссоциации растворов электролитов
- Катушка Тесла
- Экспресс-метод качественного и количественного определения анальгина в лекарственных препаратах
- Прибор для отслеживания микроклимата в учебных заведениях
- Исследование зависимости изменения выталкивающей силы соляных растворов программно-аппаратными средствами сбора и обработки данных
- Золотое сечение в архитектуре
- Проект системы автоматизированного полива выращиваемых растений (рассады) в закрытых помещениях малых площадей
- Создание WEB-приложения «Электронный библиотекарь» с функцией генерации и обработки штрих-кодов и инвентаризацией склада
- Программный расчет количества и цены пиломатериалов для возведения малометражной одноэтажной постройки с односкатной крышей
- Умный дом: новейшие технологии для реальной жизни
- Создание мобильного приложения "MoreGEO"
- Красота может быть экономной
- Робо-шаттл: автоматическое транспортное средство для аэропортов
- Исследование проходимости транспортных роботов
- Использование технологии PBR для VR-визуализации интерьера
- Воздействие электростатического поля на пламя
- Разработка и постройка беспилотного летательного аппарата (БПЛА) самолетного типа для профессионального применения
- Перечисление соответствий между конечными множествами
- Создание действующей модели мотопланера
- Антивирусный сканер InfANT
- Робот-транспортер
- Катушка Тесла
- Применение технологии Blockchain для оптимизации работы баз данных спортсменов